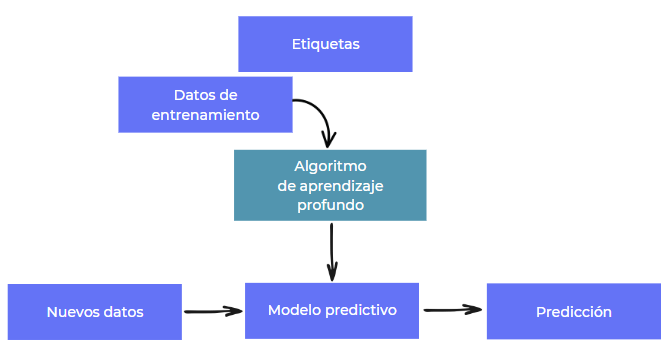
Deep Learning
Unidad 1: Fundamentos del Deep Learning
1.1 Los inicios
La idea de crear máquinas pensantes se remontan a la antigua Grecia, inspirados en figuras míticas como Pigmalión, Dédalo y Hefesto.
Sus respectivas creaciones: Galatea, Talos y Pandora, han sido considerados como las primeras formas de vida artificial.
La posibilidad de inteligencia en máquinas fue contemplada mucho antes de la existencia de las computadoras programables (Lovelace 2015).

La inteligencia artificial (IA) hoy es un campo con aplicaciones prácticas extensas y una muy prolífica agenda de investigación.
La IA moderna busca automatizar tareas rutinarias, interpretar el habla e imágenes, apoyar diagnósticos médicos y fomentar la investigación científica.
Los primeros avances en IA resolvieron problemas complejos para humanos pero simples para computadoras, definidos por reglas matemáticas formales.
El gran reto de la IA es resolver tareas intuitivas humanas, como el reconocimiento de voz o de rostros, que son difíciles de expresar con reglas formales.

1.2 Algunos personajes históricos relevantes
1.2.1 Ada Lovelace (1815-1852)
Considerada la primera programadora de la historia por su trabajo en el algoritmo destinado a ser procesado por la máquina analítica de Charles Babbage. Lovelace anticipó la capacidad de las computadoras para ir más allá del simple cálculo numérico, sugiriendo que podrían crear arte y música si se les proporcionaban las instrucciones correctas.

Acá algunos artículos que pueden ser de interés para profundizar en el tema:
1.2.2 Alan Turing (1912-1954)
Matemático y lógico británico, es uno de los padres de la informática y pionero en la inteligencia artificial. Desarrolló el concepto de la “máquina de Turing”, un dispositivo teórico que puede simular cualquier algoritmo. También es conocido por el “Test de Turing”, un criterio para evaluar la inteligencia de una máquina según su capacidad para exhibir un comportamiento indistinguible del de un humano.

Algunos artículos de interés:
1.2.3 Geoffrey Hinton
Psicólogo cognitivo y científico informático británico-canadiense, a menudo llamado “el padrino del deep learning”. Hinton ha sido una figura clave en el desarrollo de redes neuronales y algoritmos de aprendizaje profundo, contribuyendo al renacimiento del interés en la inteligencia artificial en el siglo XXI con sus avances en redes neuronales profundas.

Algunos artículos de interés:
Learning representations by back-propagating errors (Rumelhart et al. 1986).
La extensa cantidad de artículos desarrollados por Hinton puede ser revisada en Google Scholar.
1.3 Contexto actual
Los primeros éxitos de la IA ocurrieron en entornos formales y simples, como el ajedrez; por ejemplo, Deep Blue de IBM venció a Garry Kasparov en 1997.
El ajedrez, aunque estratégicamente complejo para los humanos, es simple para las computadoras debido a sus reglas formales y bien definidas.
Las tareas abstractas y formales, difíciles para los humanos, suelen ser fáciles para las computadoras, como jugar al ajedrez a nivel de campeonato.

Garry Kasparov vs Deep Blue
Ejemplo:
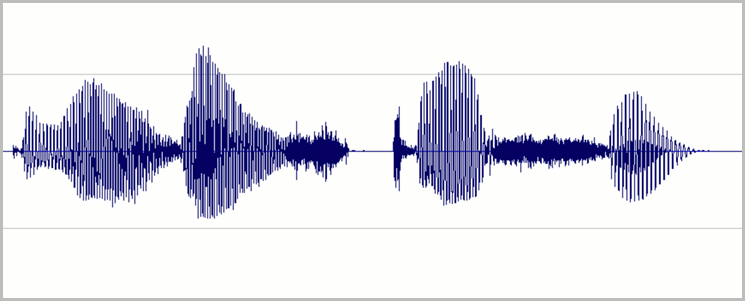
Al analizar una grabación de voz, los factores de variación incluyen la edad del hablante, su sexo, su acento y las palabras que está diciendo.
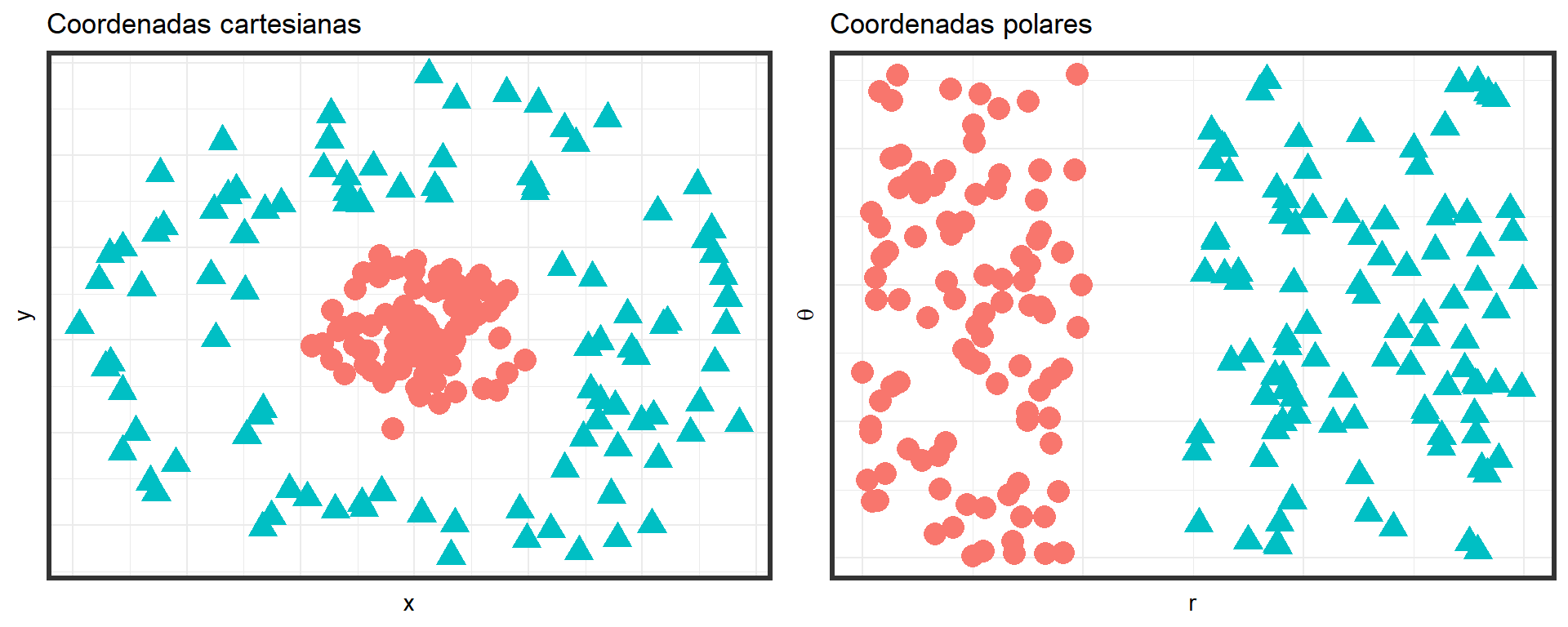
Ejemplo:
Al analizar una imagen de un automóvil, los factores de variación podrían incluir la posición del automóvil, su color y el ángulo y brillo del sol.
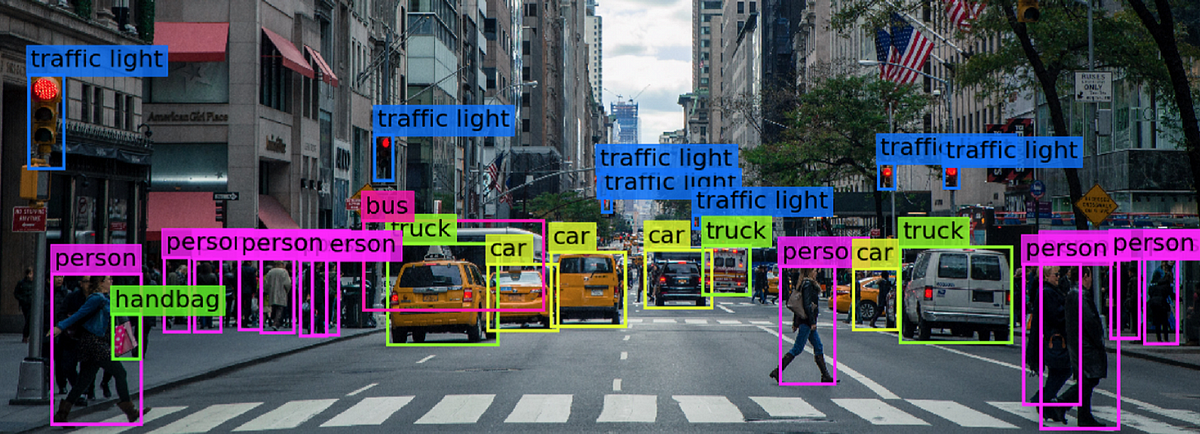
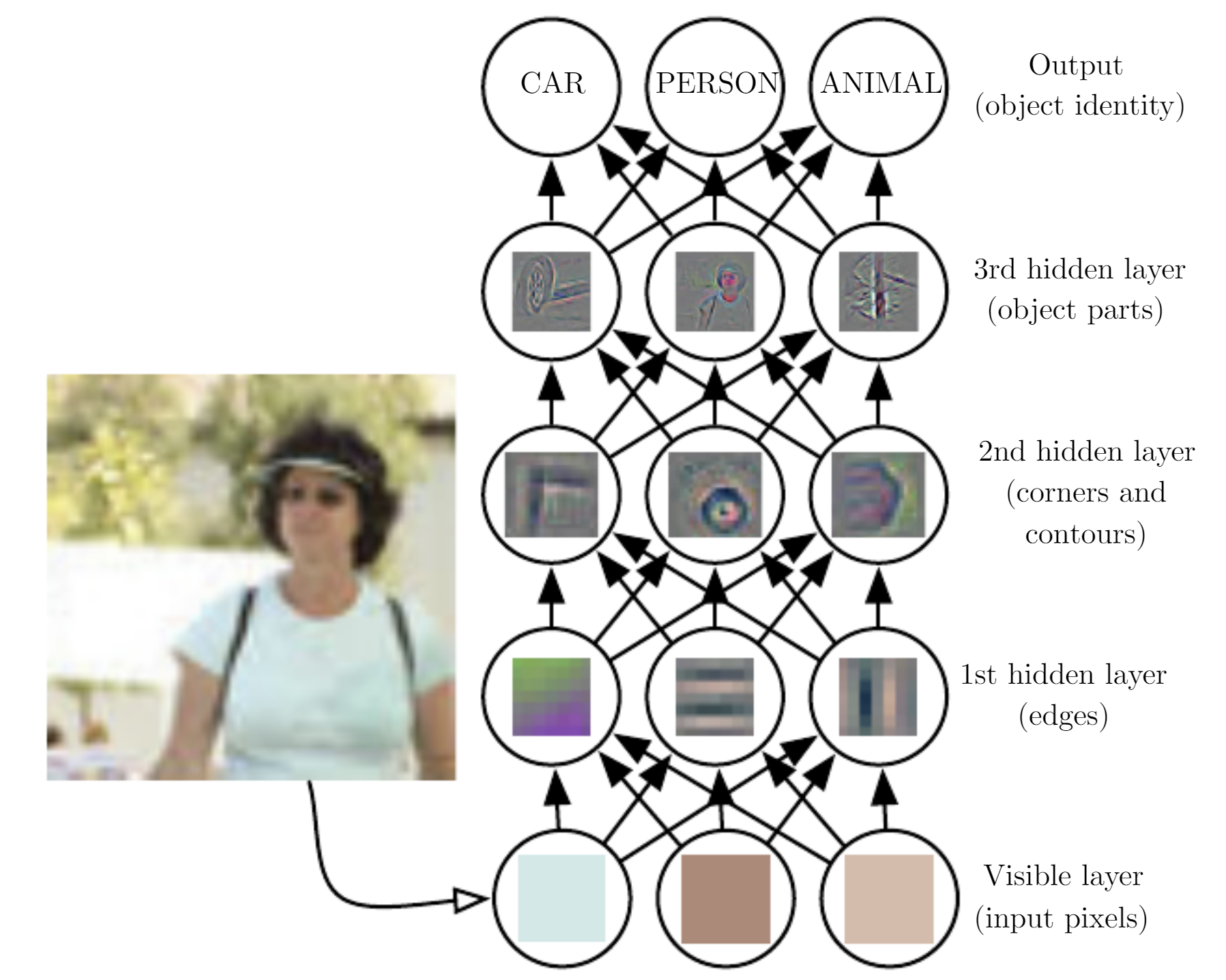
Esquema de como un sistema de aprendizaje profundo puede representar el concepto de una imagen de una persona combinando conceptos más simples, como esquinas y contornos, que a su vez se definen en términos de bordes.
Ejemplo:
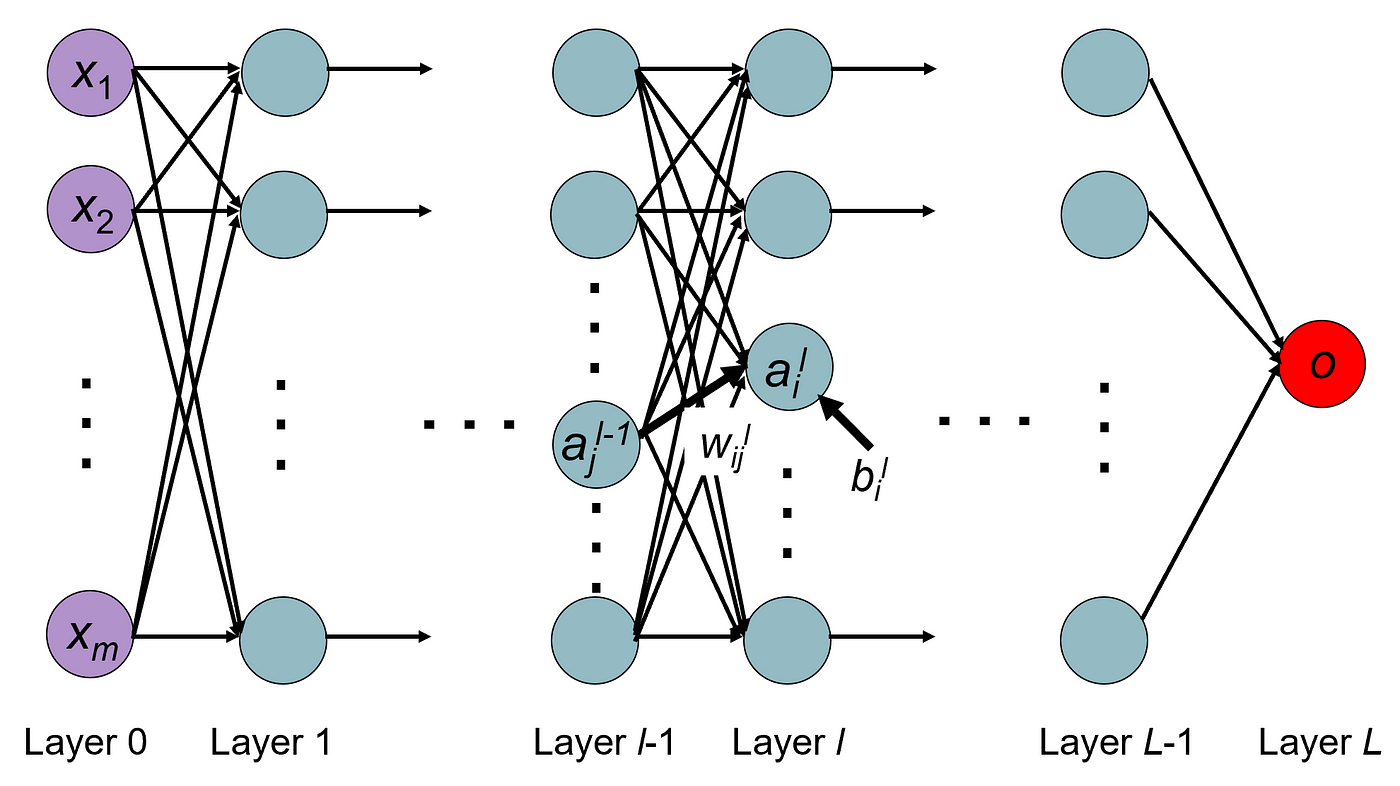
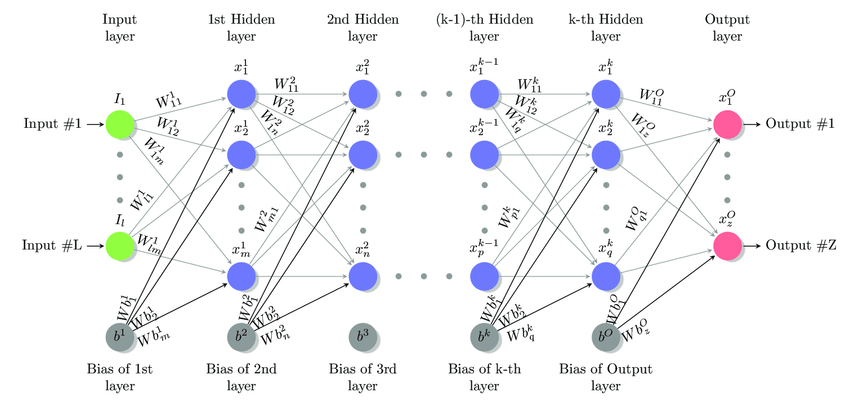
Uno de los modelos más utilizados en deep learning es la red profunda hacia adelante (deep feed forward network)o perceptrón multicapa (multilayer perceptron, MLP).
Un MLP puede ser visto como una función matemática que mapea un conjunto de valores de entrada a valores de salida.
La función se forma componiendo muchas funciones más simples. Podemos pensar en cada aplicación de una función matemática diferente como proporcionando una nueva representación de la entrada.
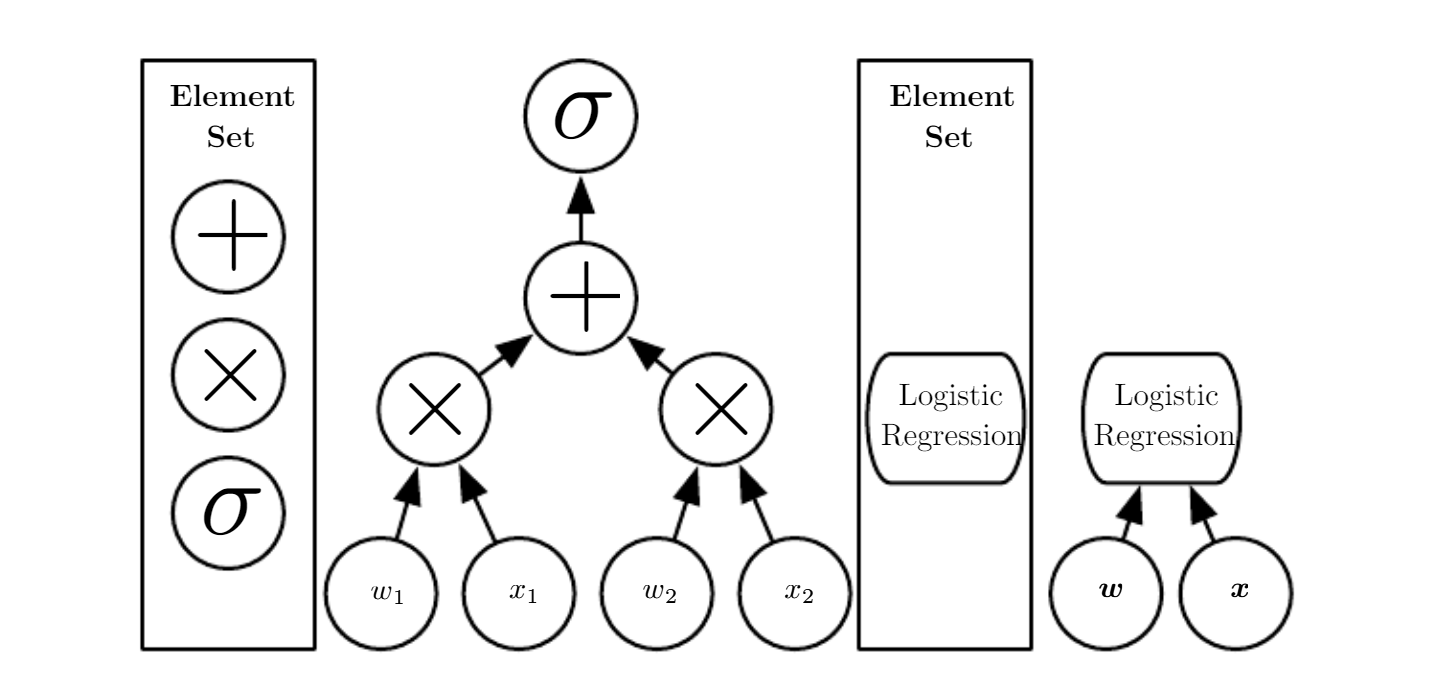
Ejemplo: Regresión logística
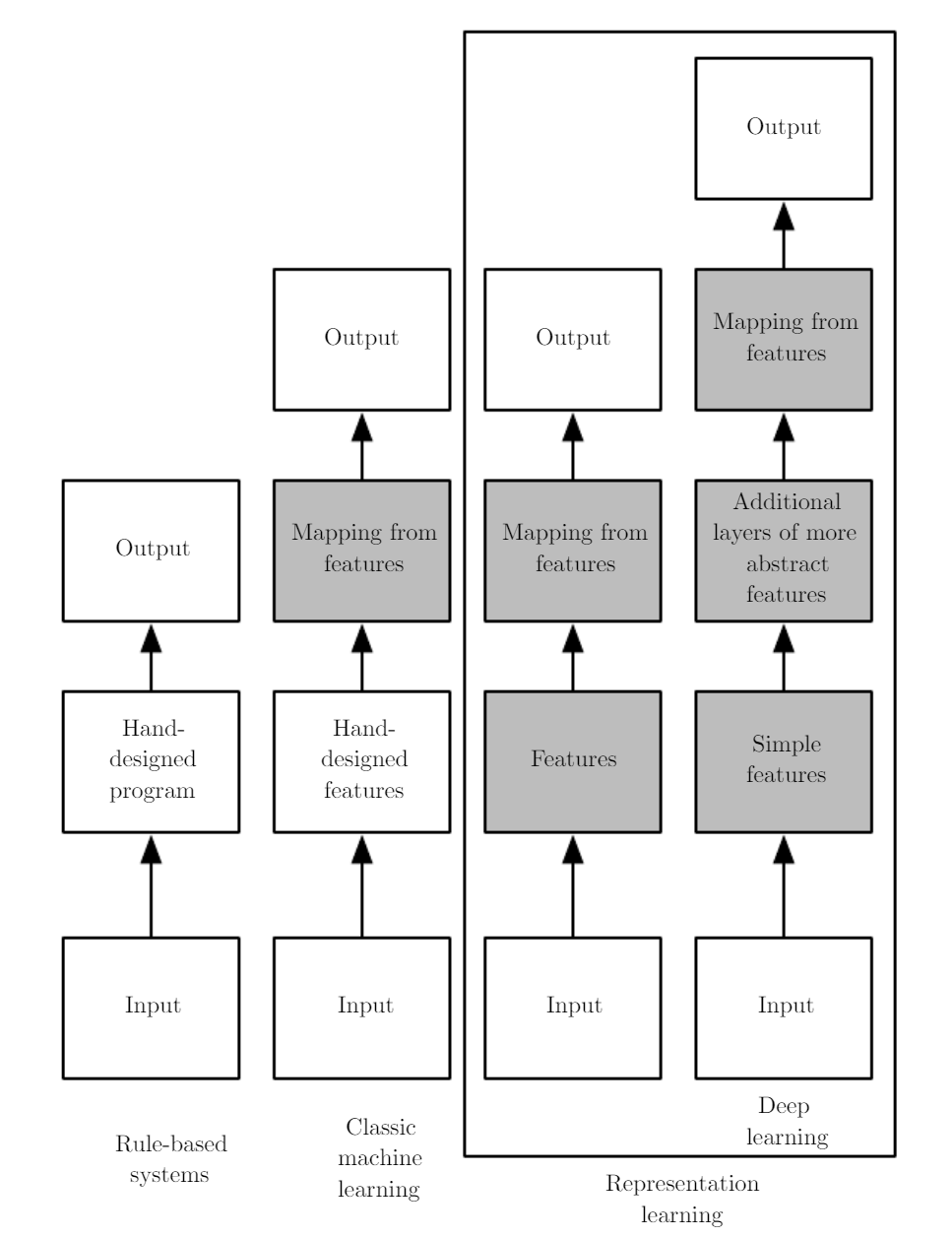
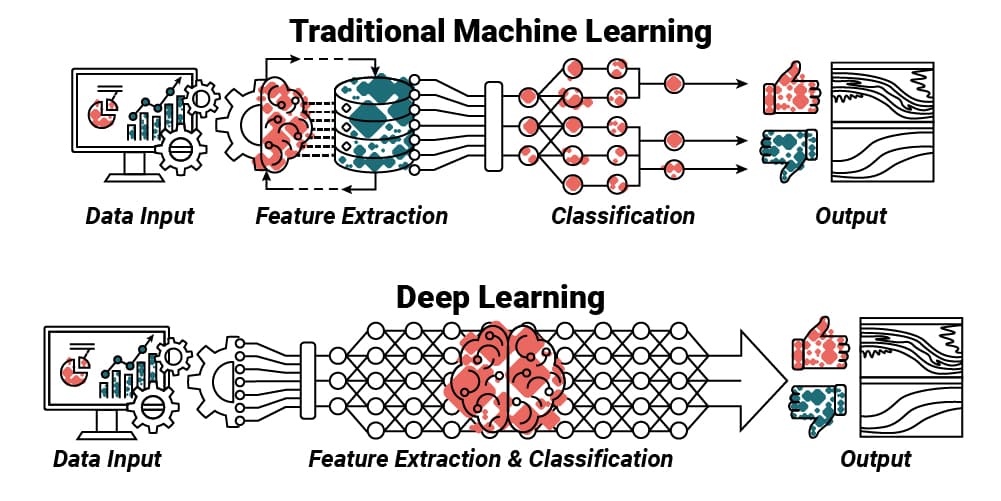
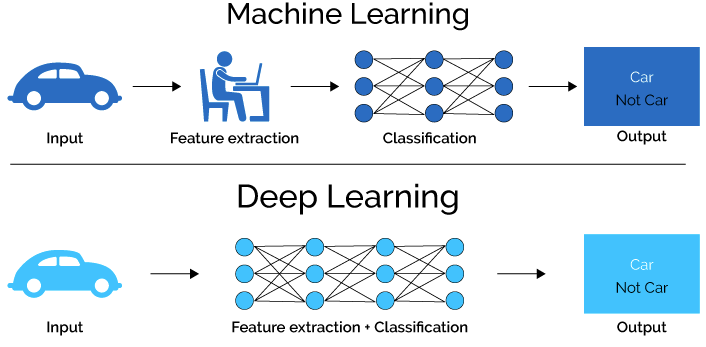
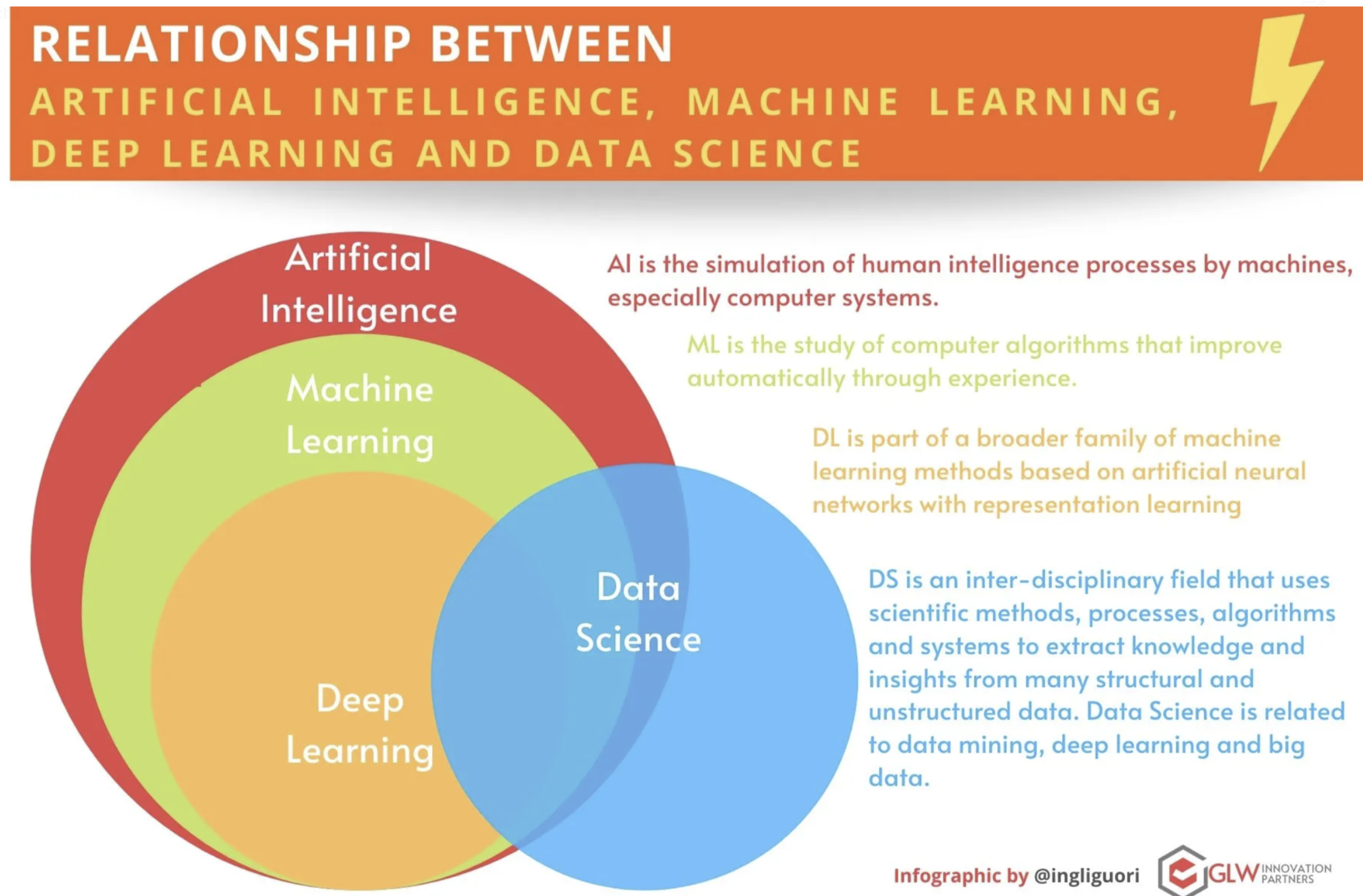
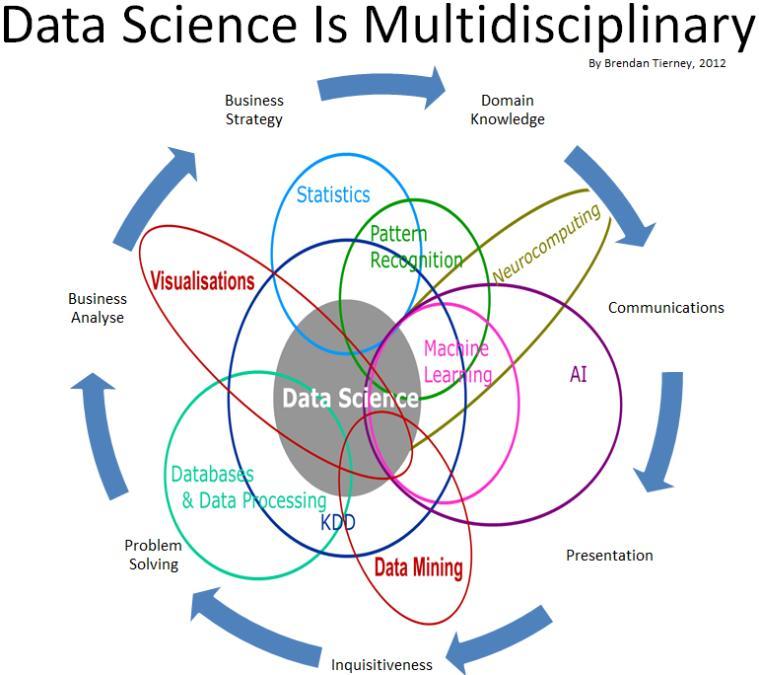
1.5.1 Redes Neuronales y sus múltiples nombres
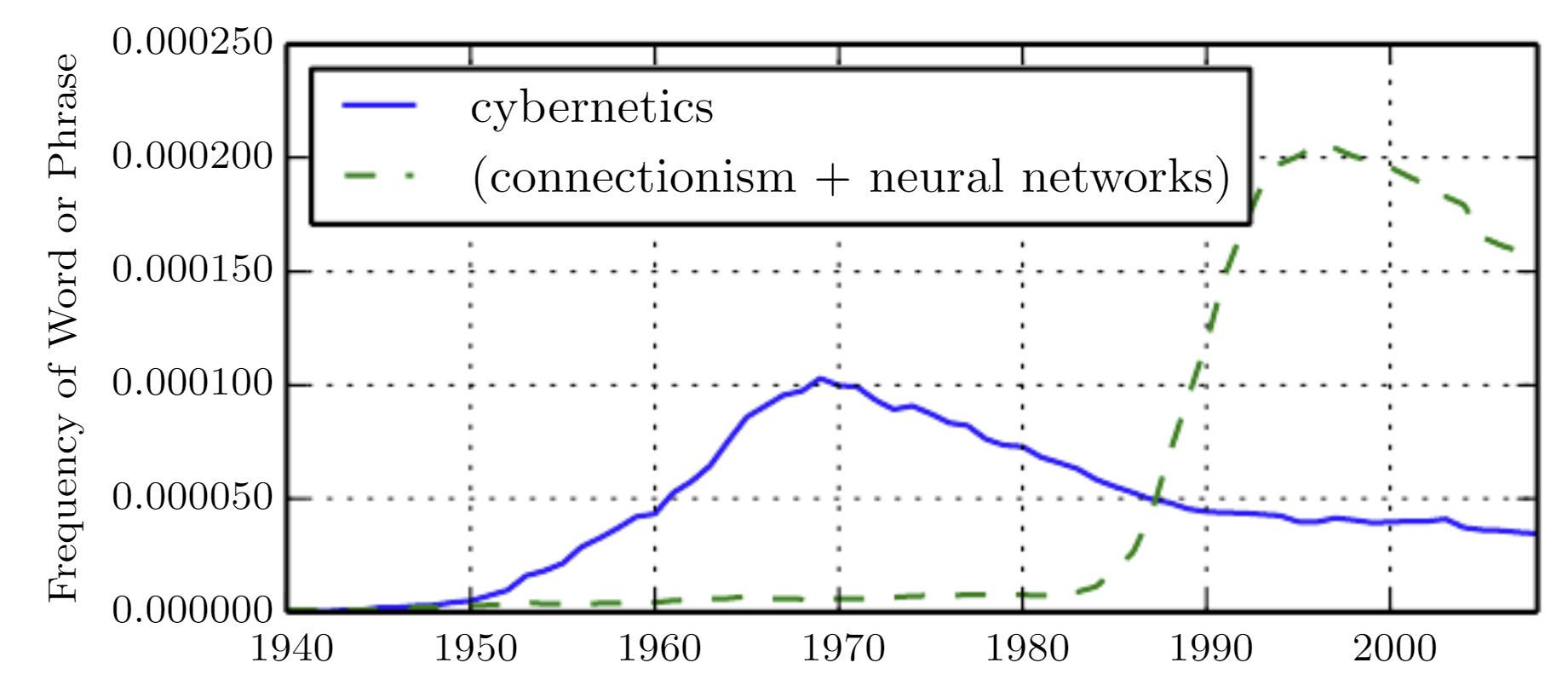
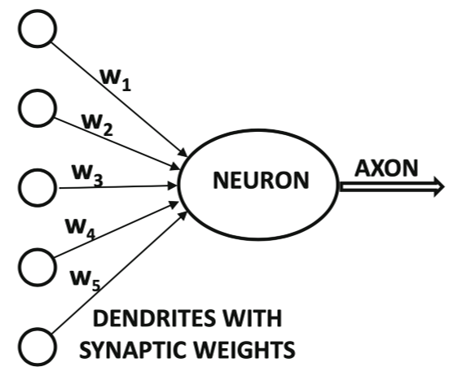
Los primeros predecesores de lo que conocemos hoy como Deep Learning fueron modelos mucho más simples, motivados desde una perspectiva neurocientífica.
Estos modelos fueron diseñados para tomar un set de valores de entrada (inputs) \(x_1, \ldots, x_n\) y luego asociarlos con un valor de salida (output) \(y\). Estos modelos podrían aprender un set de pesos (weights) \(w_1, \ldots, w_n\) y computar el valor de salida \(f(\mathbf{x}, \mathbf{y} ) = x_1 w_1, \ldots, x_n w_n\).
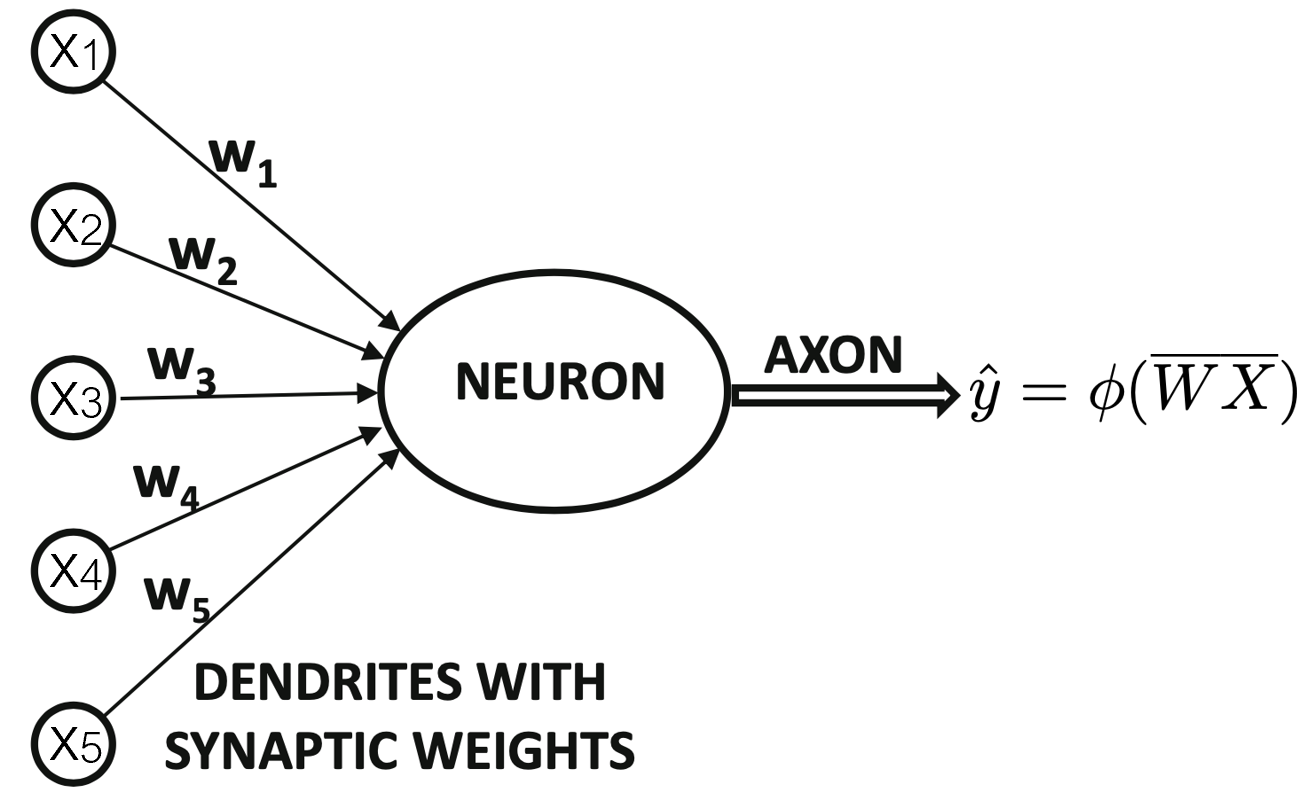
1958, Frank Rosenblatt creó el perceptrón.
1962, primer algoritmo de entrenamiento para el perceptrón: \(\mbox{Cambio de Peso} = (\mbox{Valor de línea de Peso Previo})\frac{\mbox{Error}}{\mbox{Número de Entradas}}\)
Alrededor de la misma época, un artículo afirmó que no podría ser una extensión de la red neuronal de una sola capa a una red neuronal de múltiples capas.
1986-2005 se encontraron varios retos computacionales, de estabilidad y de sobreajuste en el uso de este algoritmo.
2006, Hinton, Salakhutdinov, Osindero y Teh demostraron que las redes neuronales feedforward de múltiples capas podían preentrenarse eficazmente una capa a la vez, comenzando la era del aprendizaje profundo.
2009 las redes neuronales de aprendizaje profundo fueron entrenadas con unidades de procesamiento gráfico (GPU) de Nvidia.
Desde entonces, múltiples arquitecturas han sido reconsideradas y creadas resolviendo problemas específicos.
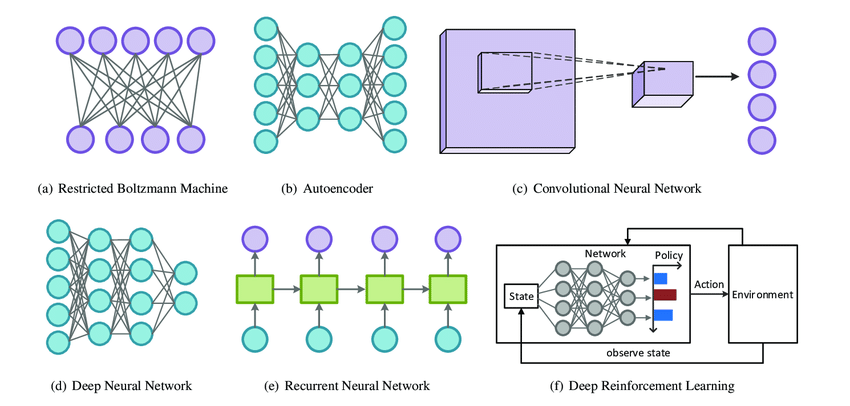
Profundizando un poco en la historia
Para más detalles, se puede revisar el libro de Deep Learning (ver Goodfellow et al. 2016, 12-26).
Hay muchos recursos en internet para encontrar información histórica asociada a Deep Learning, por ejemplo:

1.5.2 Crecimiento de datasets


Infografía Data never sleeps de Domo
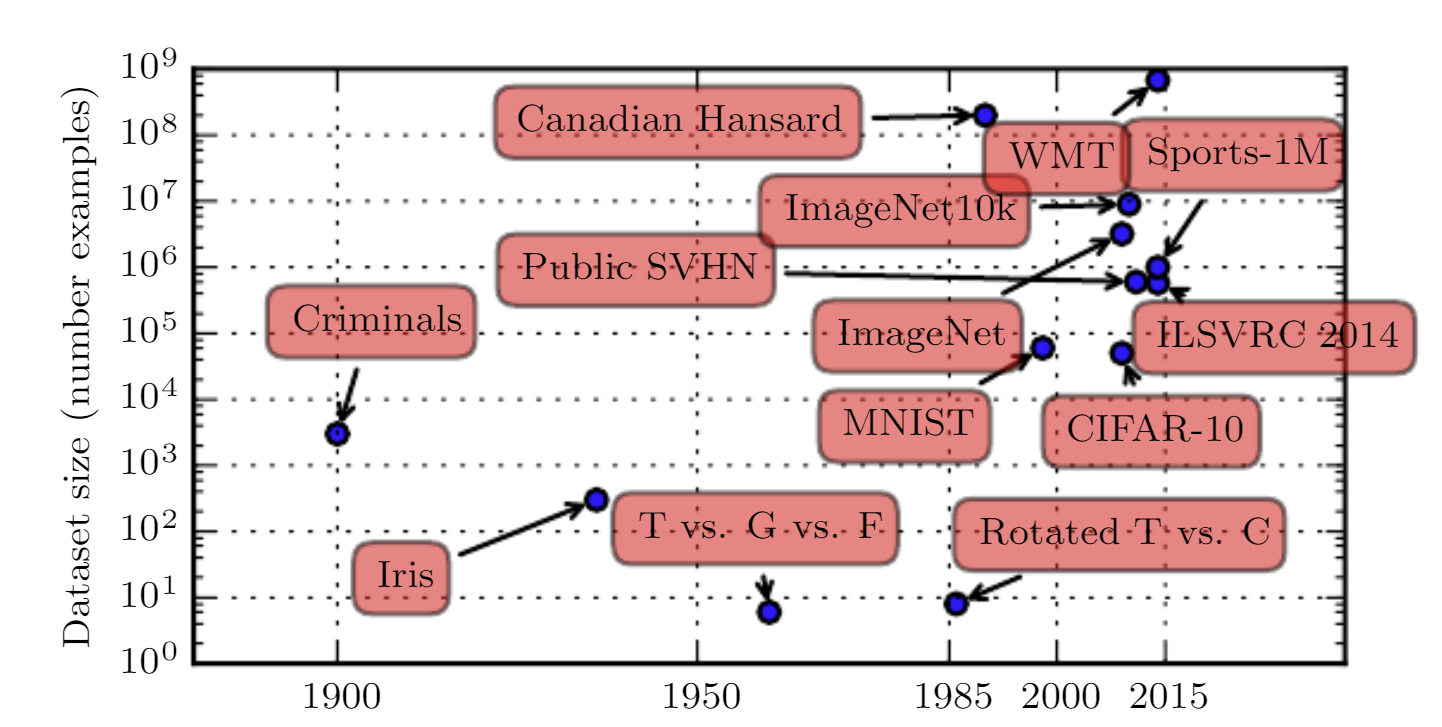
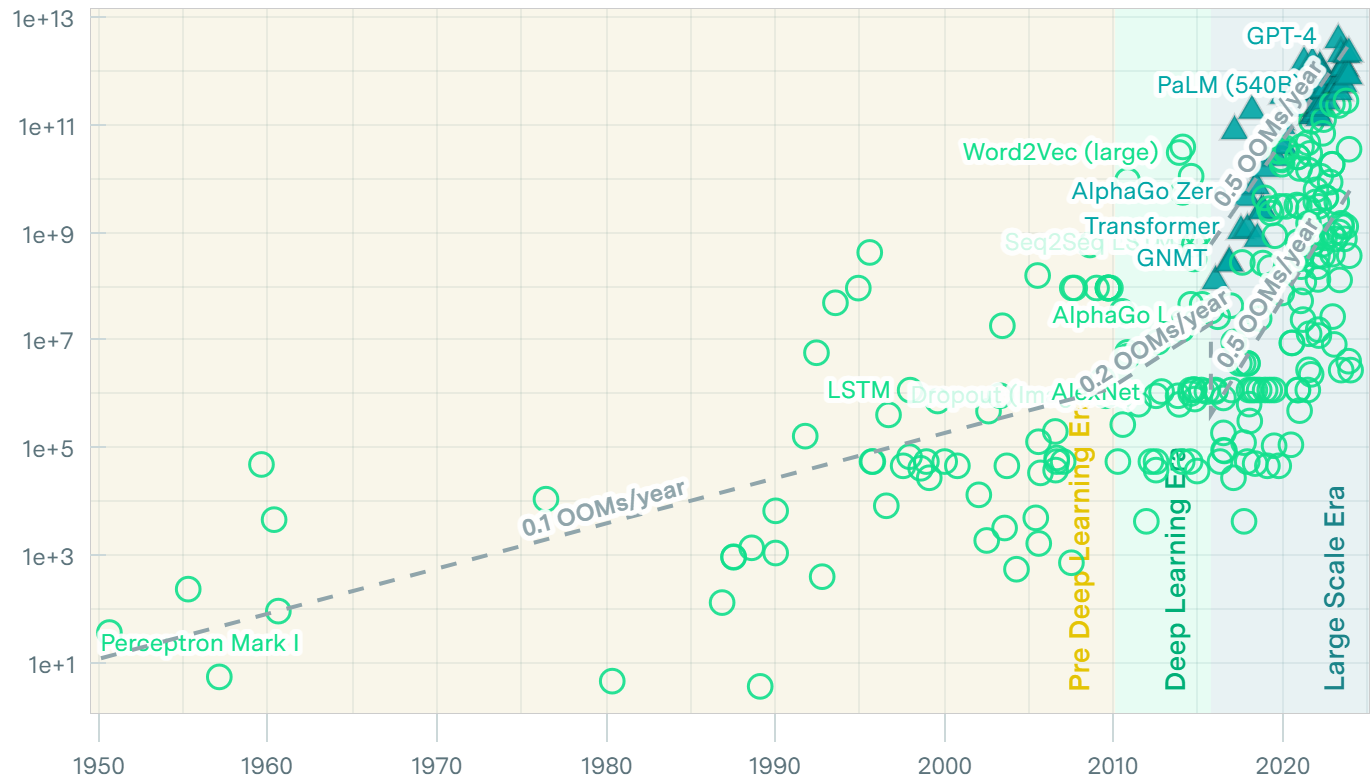
1.5.3 Modelos más complejos
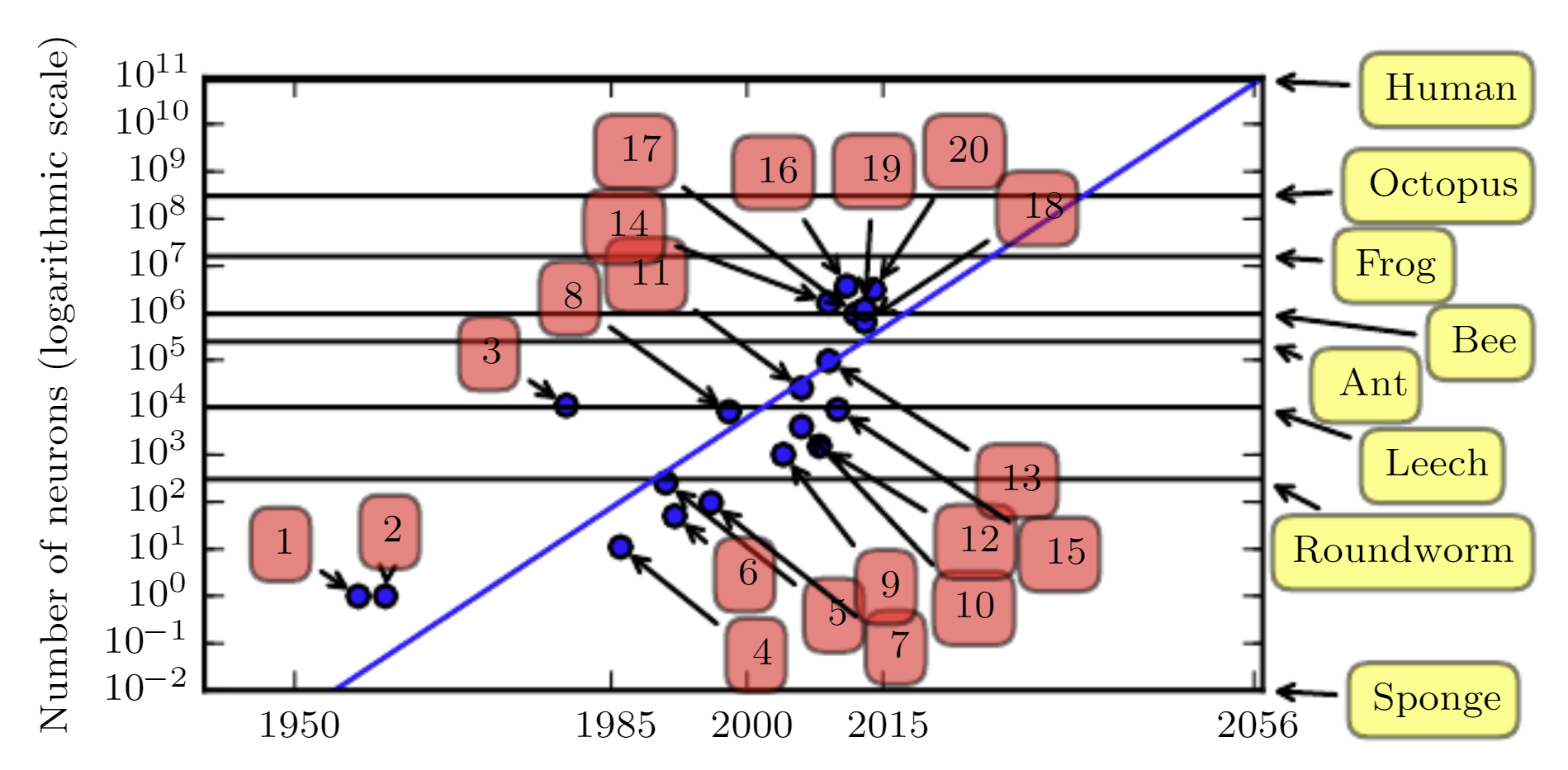
Número de neuronas asociado a la complejidad de los modelos de DL (Goodfellow et al. 2016).
1.5.4 Crecimiento en el desempeño de los modelos
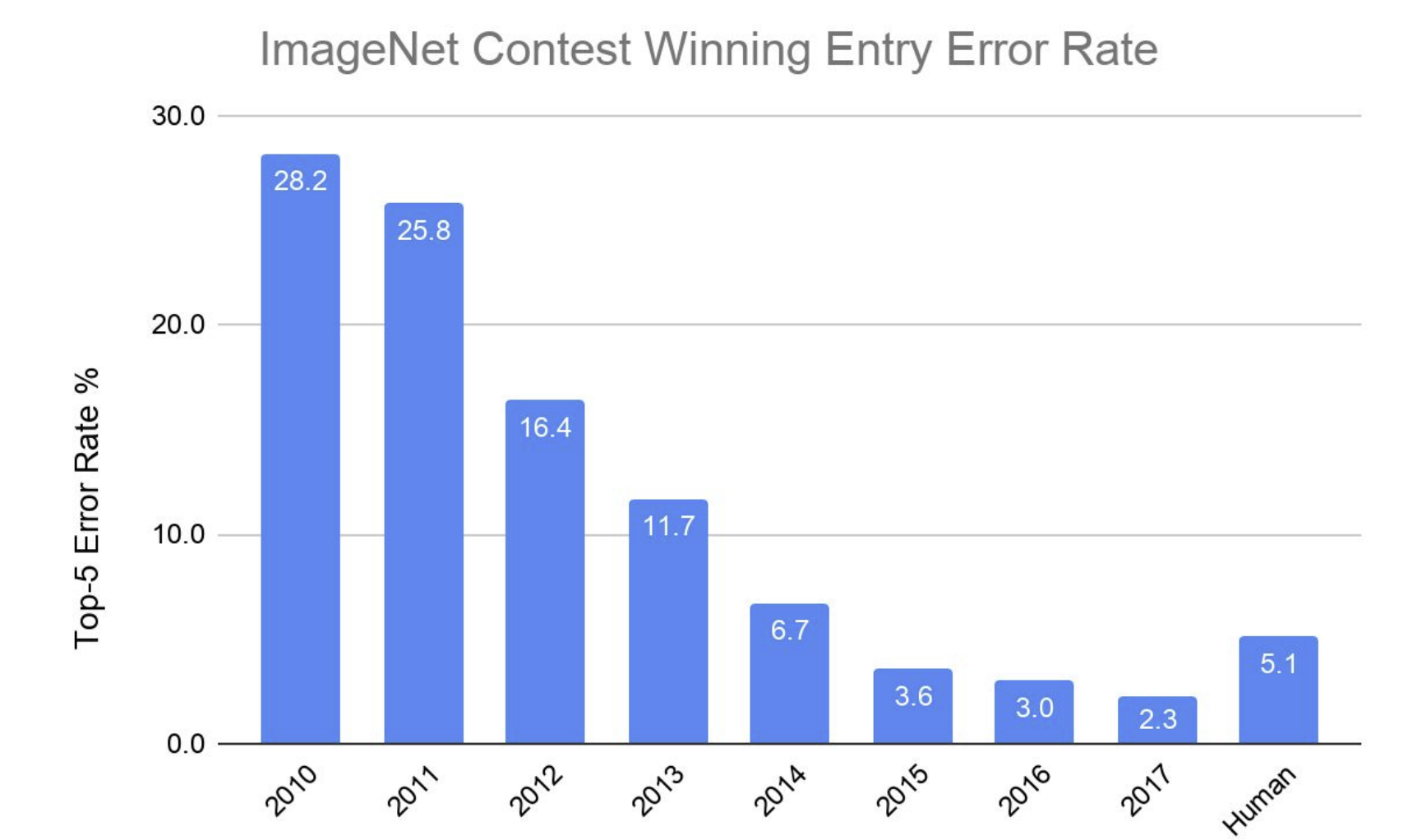
Resultados del error obtenido por los ganadores de la competencia de clasificación ImageNet, figura extraída de Dean (2019).
Aprendizaje supervisado
Los datos consisten en algunos puntos y una etiqueta o valor objetivo asociado a ellos.
El objetivo de los algoritmos es encontrar alguna manera de estimar ese valor objetivo.
Usualmente utilizados como etapa final de algún proyecto de ciencia de datos, asociado a clasificación o regresión.
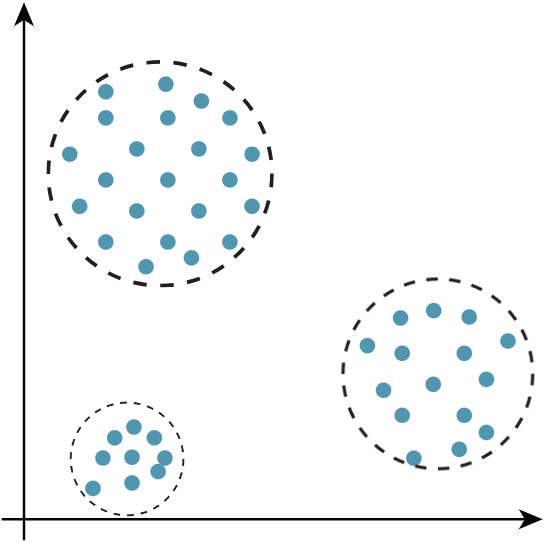
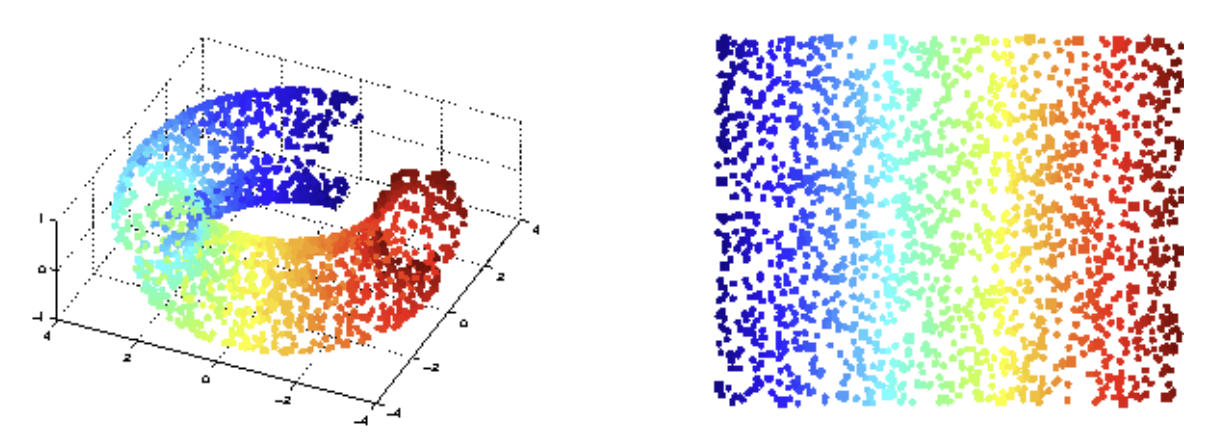
Aprendizaje no supervisado
En este caso, solo se tiene datos en bruto, sin ninguna etiqueta ni objetivo a ser predicho.
Los algoritmos no supervisados se emplean para encontrar patrones en los datos, buscando en su estructura subyacente.
Usualmente usados como parte del pre procesamiento de los datos.
Algoritmos de agrupamiento (clustering), por ejemplo, intentan separar los datos en agrupaciones naturales.
Aprendizaje reforzado
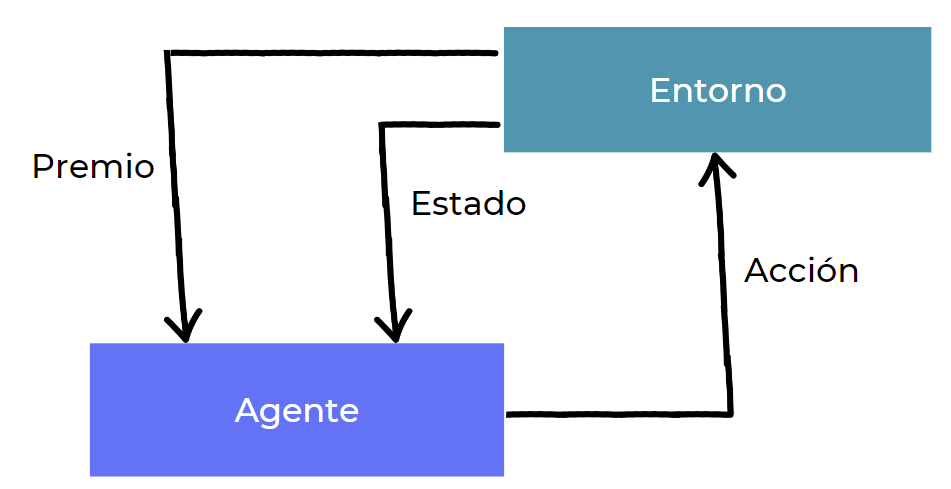
Algoritmos más utilizados: Q-learning y DQN (Deep Q network)
-
Ejemplos de entornos donde se utiliza:
Juegos
Manejo de recursos
Recomendaciones personalizadas
Robótica
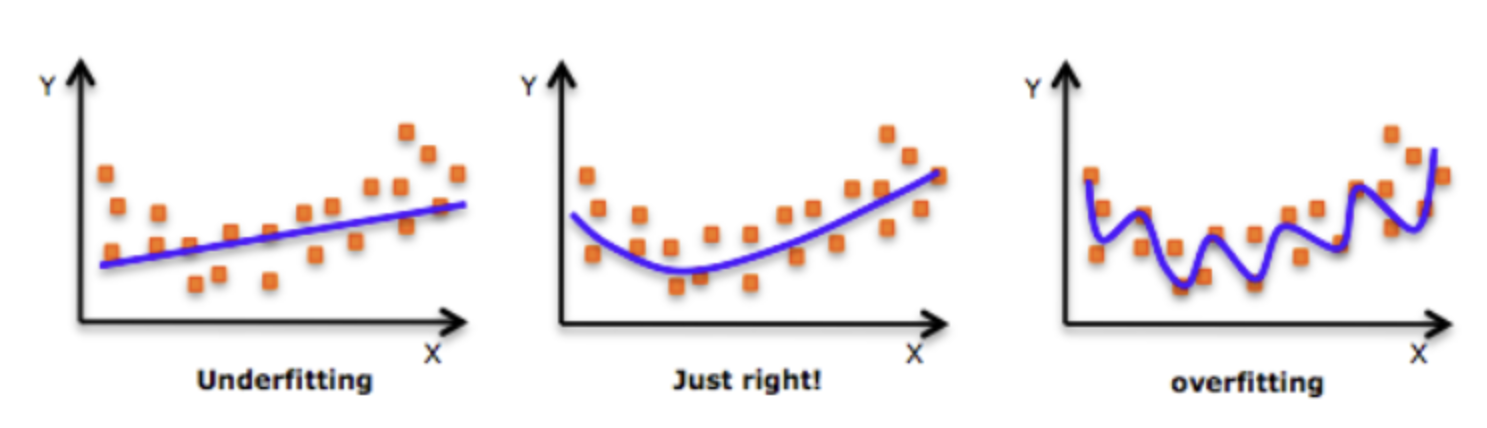
2.2 Sub y sobre entrenamiento
Los factores que determinan la capacidad de desempeño de in algoritmo de aprendizaje automático son las habilidades para:
Hacer el error de entrenamiento lo más pequeño posible
Hacer que la brecha entre error de entrenamiento y prueba sea lo más pequeño posible


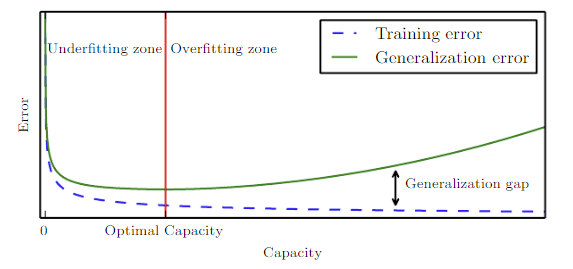
Zona de infraajuste: En el extremo izquierdo del gráfico, donde ambos errores, de entrenamiento y de generalización, son altos.
Capacidad óptima: Punto en el eje de capacidad donde el error de generalización es mínimo antes de que comience a aumentar nuevamente.
Brecha de generalización: La diferencia entre el error de entrenamiento y el error de generalización; se amplía a medida que la capacidad excede la óptima.
Zona de sobreajuste: Área a la derecha de la línea roja vertical, donde la capacidad es demasiado grande y el error de generalización es más alto debido a una brecha de generalización más amplia.
3.1 Redes Neuronales Profundas
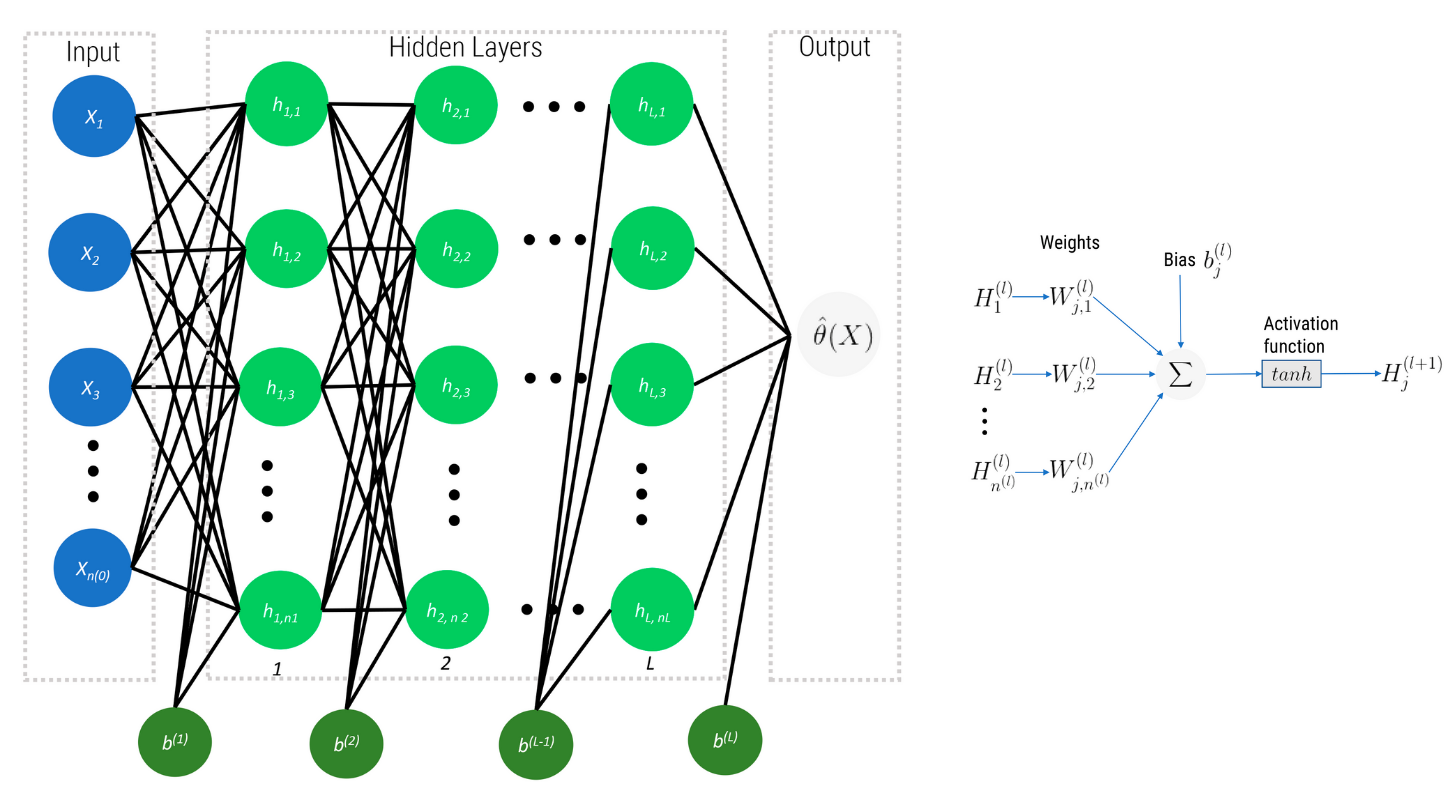
Esquema de una red neuronal profunda (Deep Feed Forward Networks, DFFN)
3.2 Redes Neuronales Convolucionales
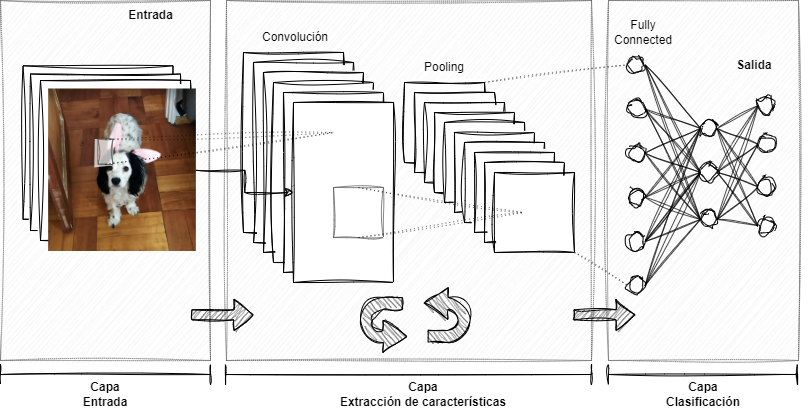
Esquema de una red neuronal convolucional (Convolutional Neural Networks, CNN)
3.3 Redes Neuronales Recurrentes
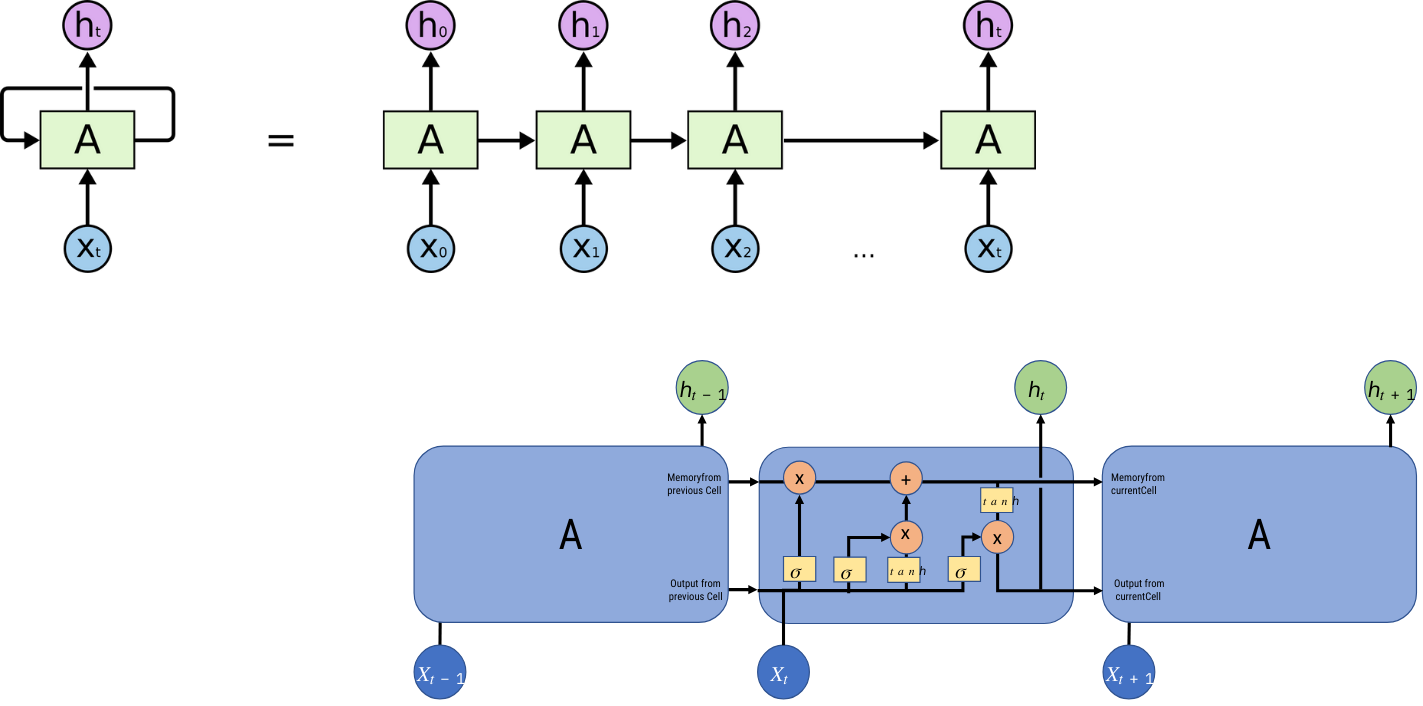
Esquema de una red neuronal Long Short Term Memory (LSTM)
3.4 Modelos Generativos Adversariales
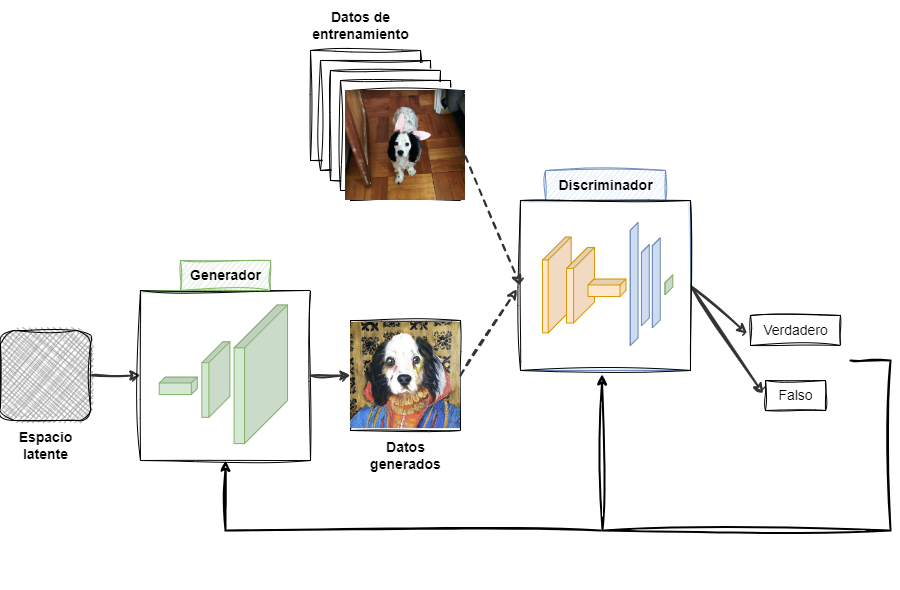
Esquema de una red generativa adversarial (Generative Adversarial Network, GAN)
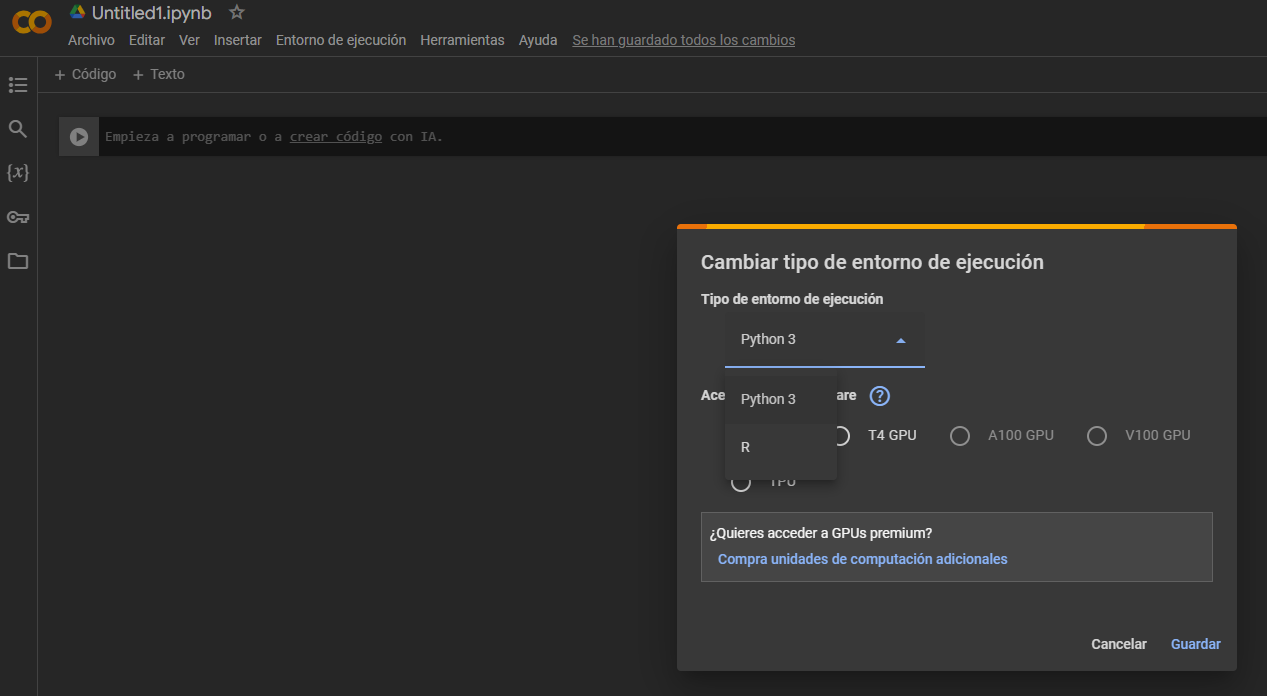
4.1.3 Google Colab
También podremos emplear Google Colab para ejecutar nuestro código de manera online. Esto tiene algunas ventajas y desventajas.