Deep Learning
Unidad 2: Perceptrones Multicapa (MLP) y Deep Learning
Una red neuronal artificial, ANN por sus siglas en inglés artificial neural network modelan la relación entre un conjunto de señales de entrada y una señal de salida usando un modelo derivado desde nuestro entendimiento de cómo funciona un cerebro biológico ante estimulos externos.
Tal como un cerebro usa una red de células interconectadas llamadas neuronas, una red neuronal usa una red de neuronas artificiales o nodos para resolver problemas de aprendizaje.
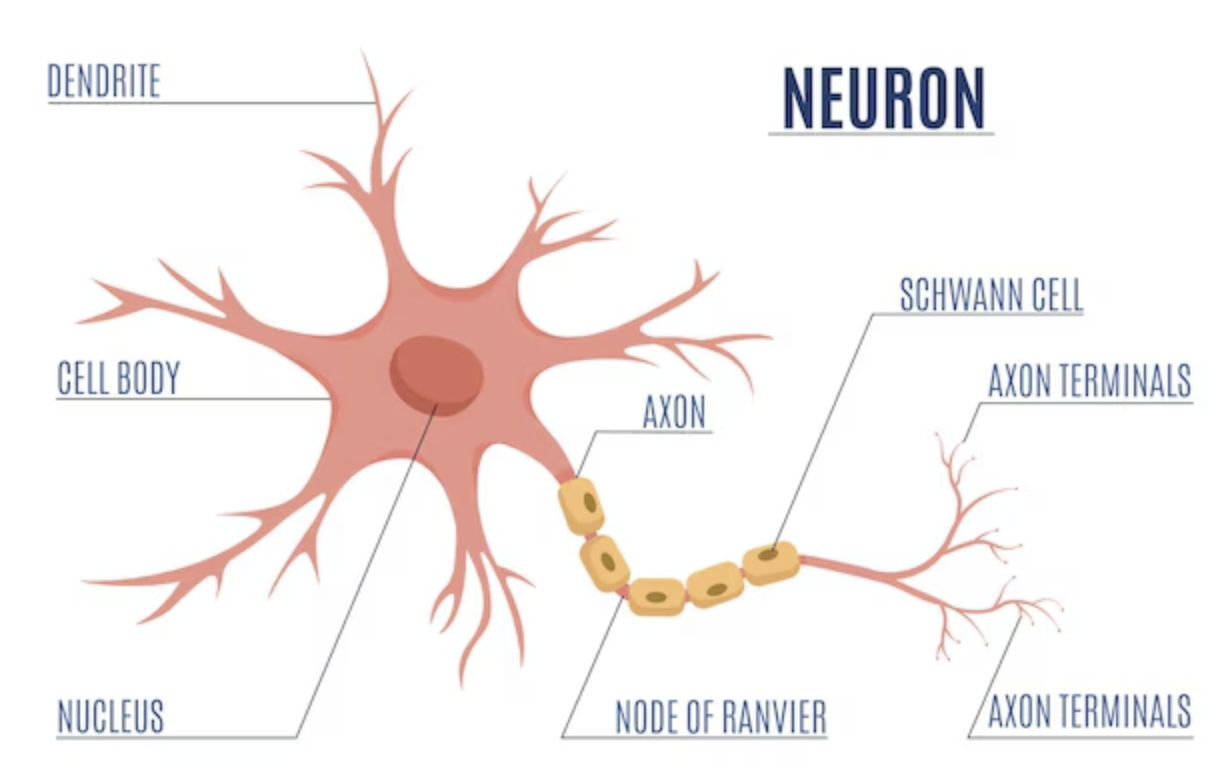
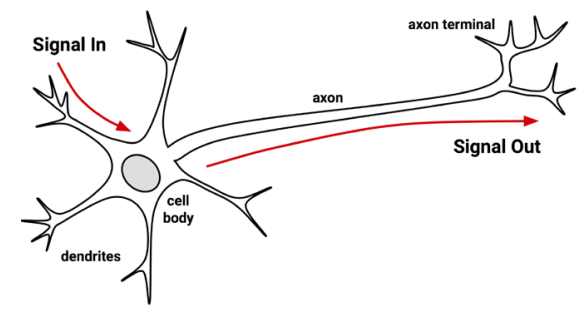
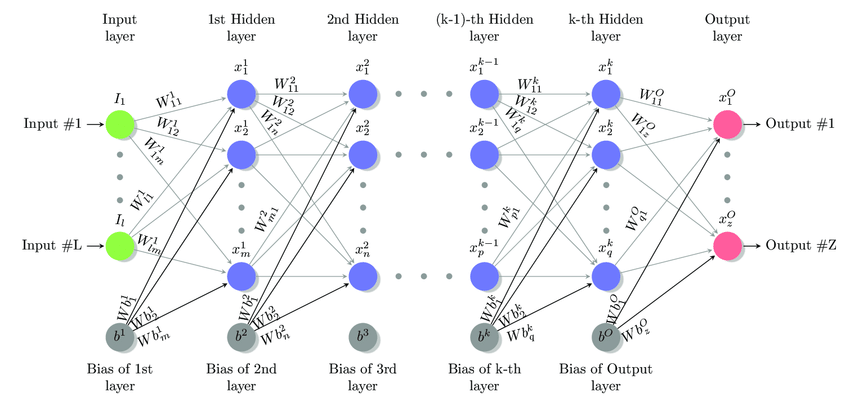
Red neuronal artificial
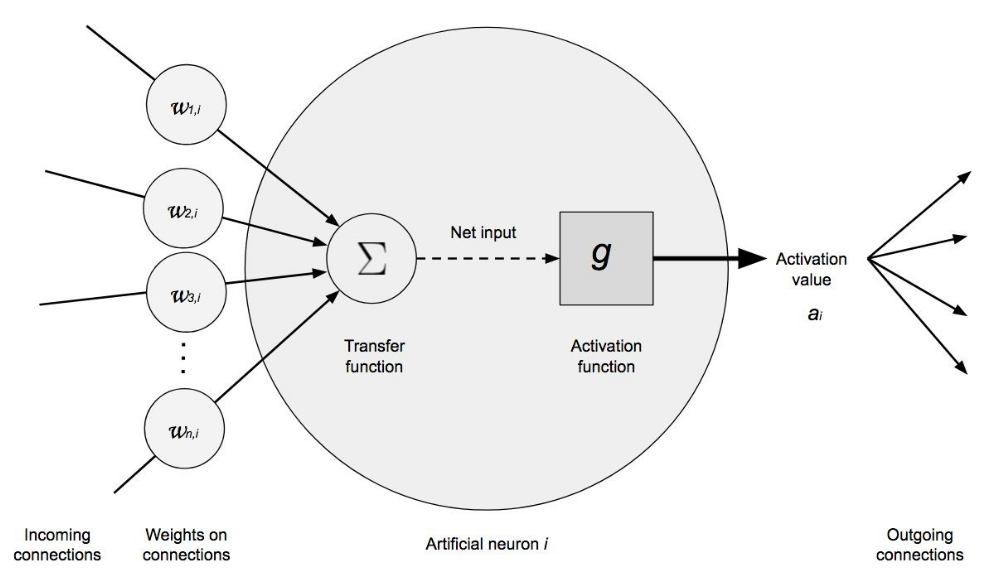
Neurona
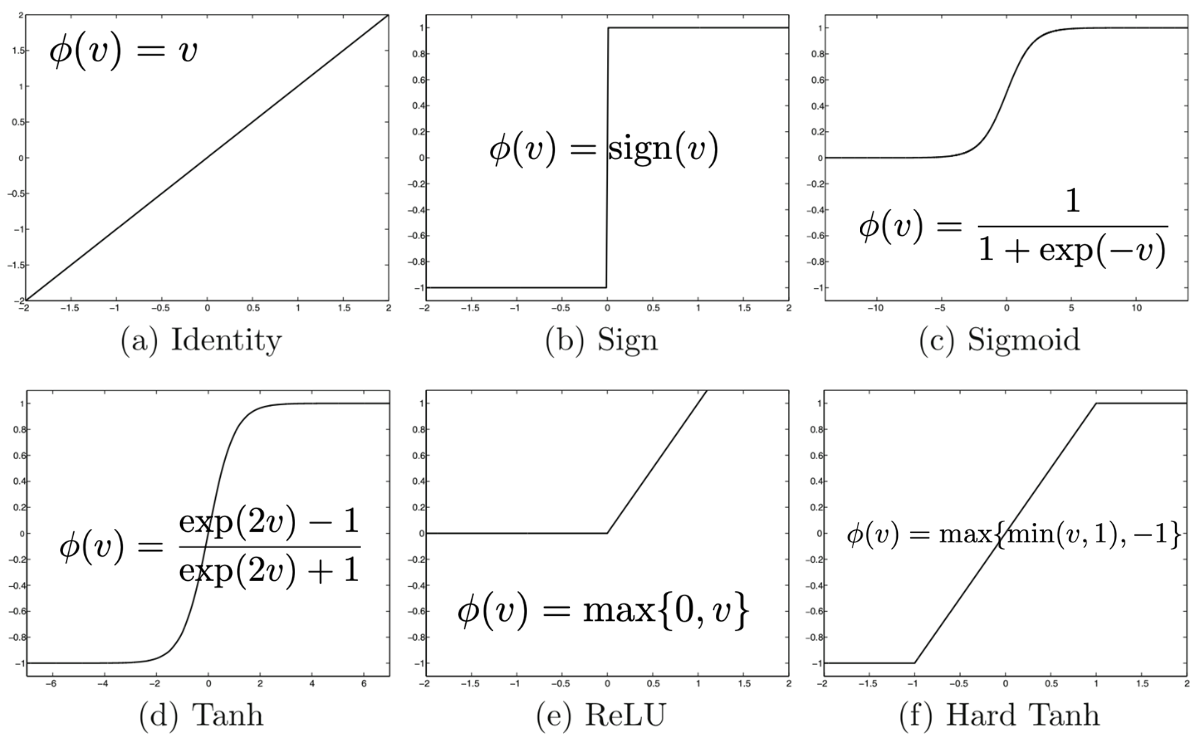
3.1.1 Sigmoide
La función sigmoide transforma valores en la recta real a valores en el rango \([0, 1]\):
\[sigmoid(x)=\dfrac{1}{1+\exp(-x)}\]
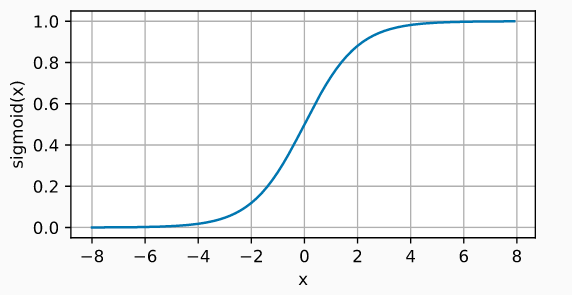
Sigmoid
3.1.2 Tangente hiperbólica
La función de activación Tanh, se comporta de forma similar a la función sigmoide, pero su salida está acotada en el rango \([-1, 1]\):
\[\tanh(x)=\dfrac{1-\exp(-2x)}{1+\exp(-2x)}\]
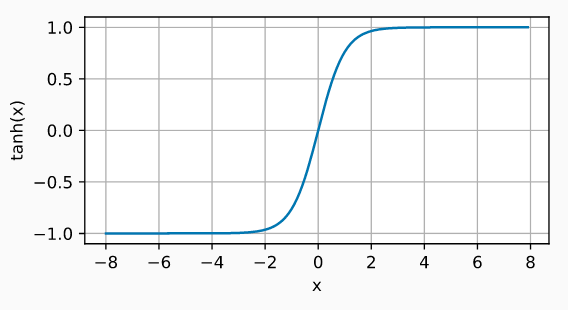
Tangente hiperbólica
3.1.3 Rectified linear unit (ReLU)
La función de activación ReLu aplica una transformación no lineal muy simple, activa la neurona solo si el input está por encima de cero. Mientras el valor de entrada está por debajo de cero, el valor de salida es cero, pero cuando es superior, el valor de salida aumenta de forma lineal con el de entrada.
\[ReLU(x)=\max (0,x)\]
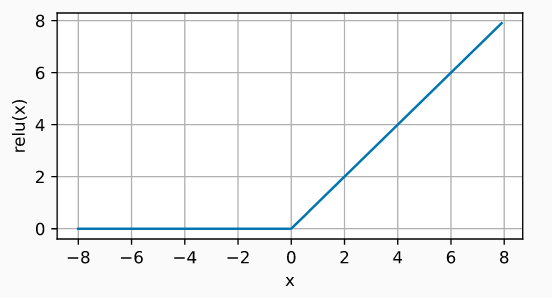
Rectified linear unit
3.1.4 Gaussian Error Linear Unit (GELU)
Se considera una mejora sobre las funciones de activación tradicionales como ReLU, debido a sus propiedades suaves y no lineales.
\[ GELU(x) = x \cdot \Phi (x)\] donde \(Phi(x)\) representa la CDF de la distribución normal estándar.
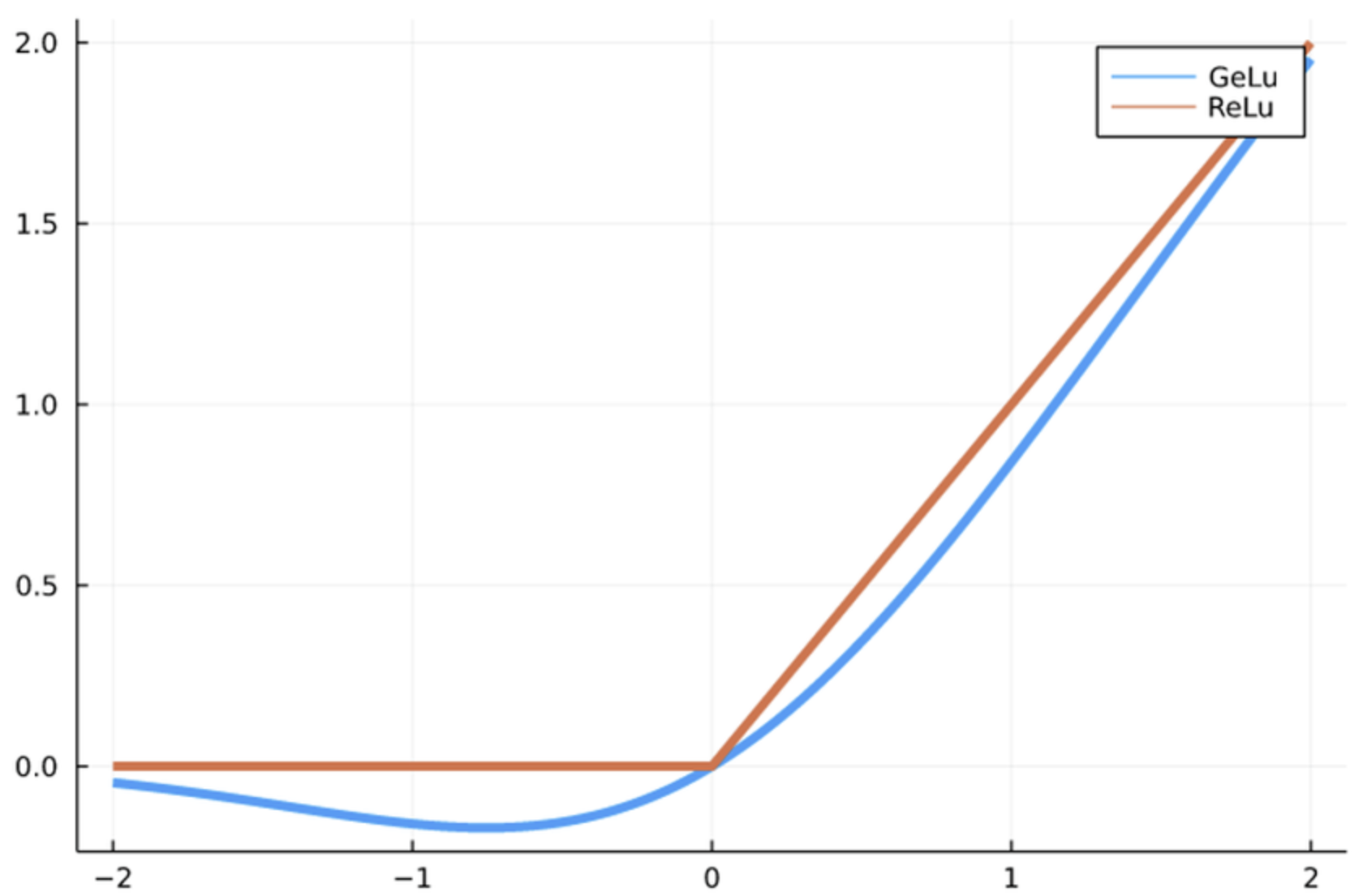
Gaussian Error Linear Unit
3.1.5 Funciones de activación y sus usos
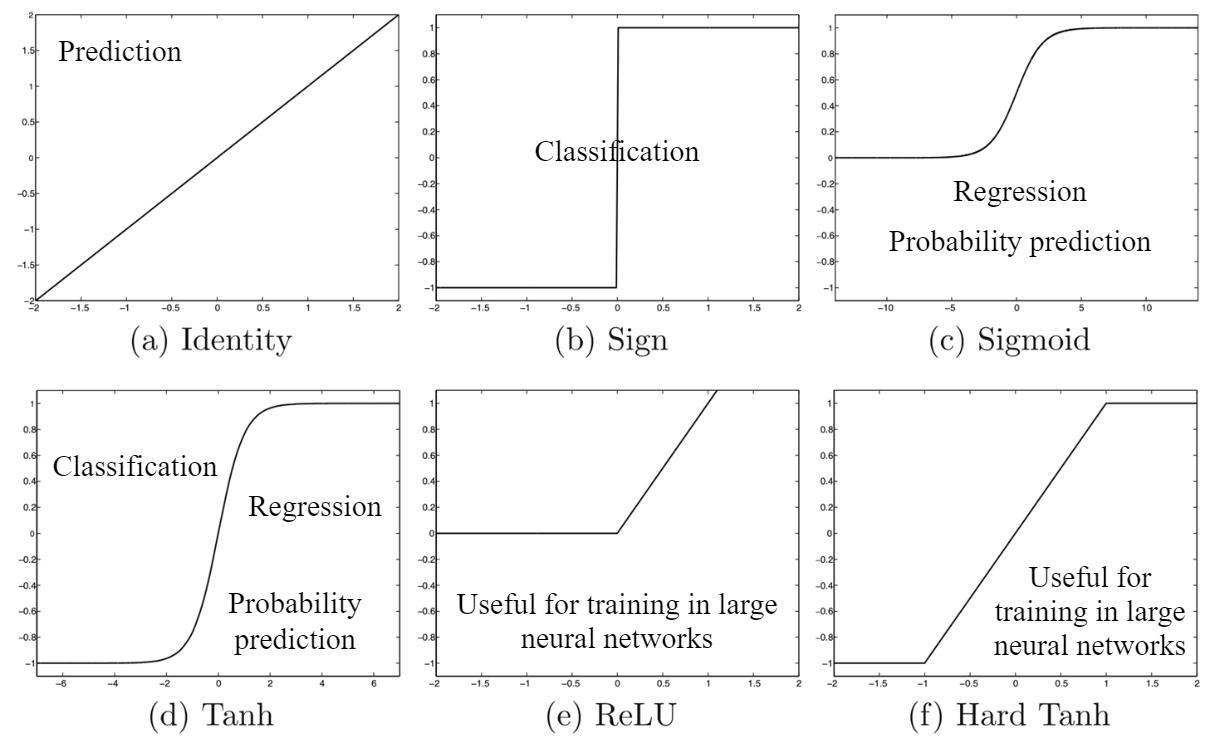
Ejemplos de perceptrones y funciones de activación
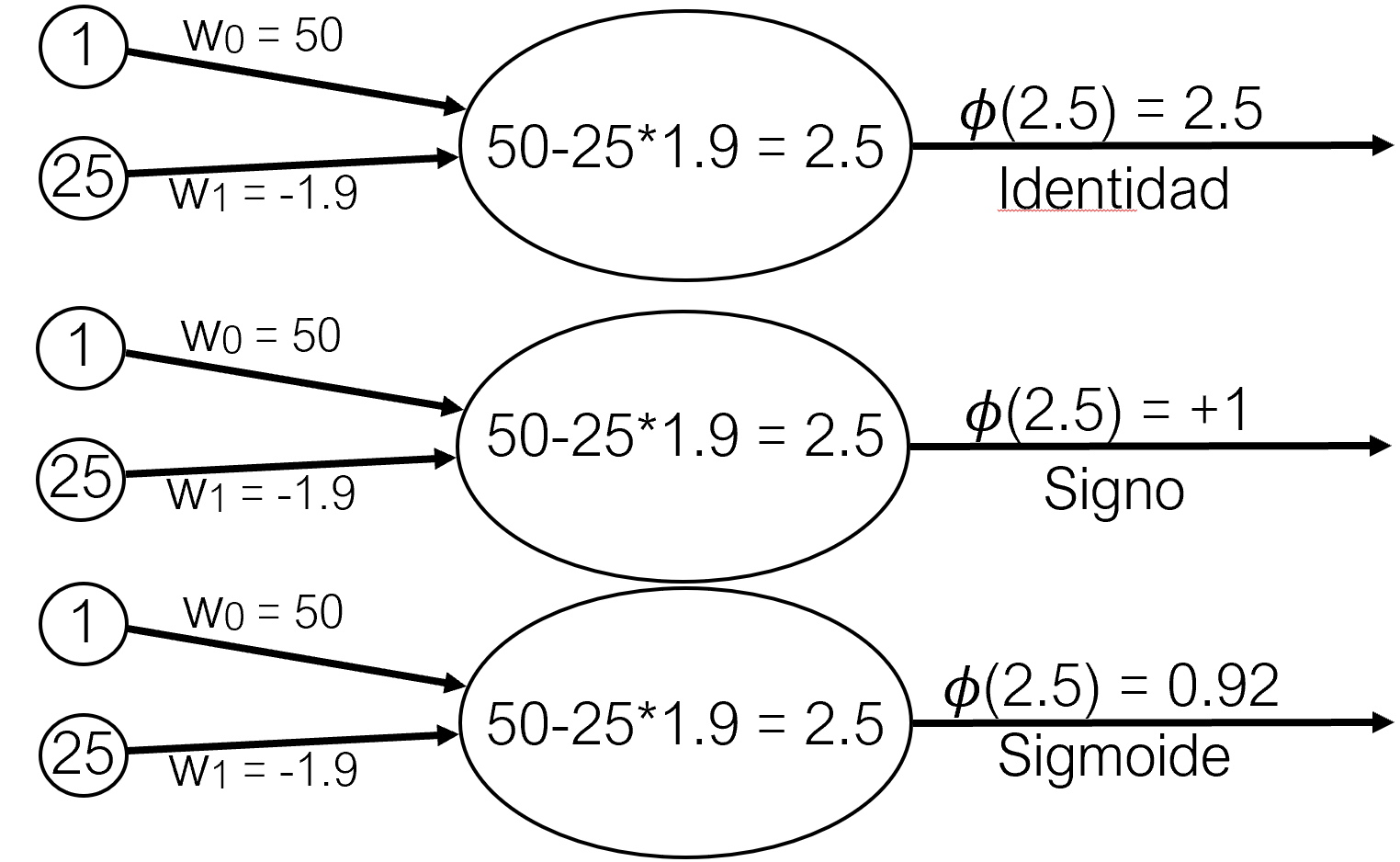
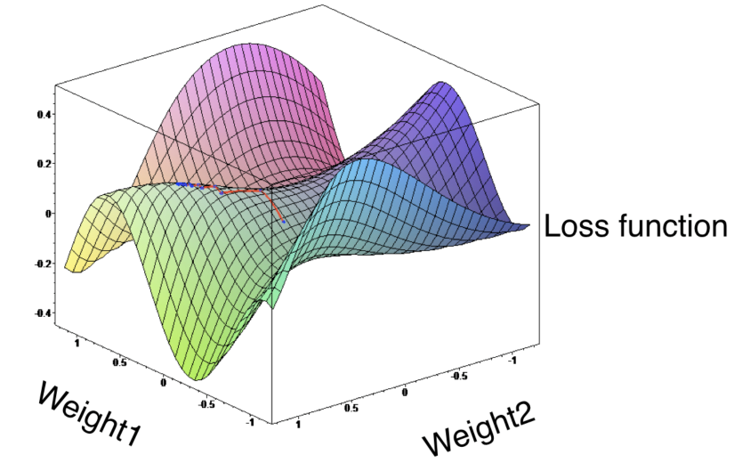
La función de coste (\(l\)), también llamada función de pérdida, loss function o cost function, es la encargada de cuantificar la distancia entre el valor real y el valor predicho por la red, en otras palabras, mide cuánto se equivoca la red al realizar predicciones.
En la mayoría de casos, la función de coste devuelve valores positivos. Cuanto más próximo a cero es el valor de coste, mejor son las predicciones de la red (menor error), siendo cero cuando las predicciones se corresponden exactamente con el valor real.

Distintos objetivos de un modelo.
perceptrón multicapa
En el proceso de entrenamiento, se busca el mejor conjunto de parámetros para minimizar alguna de las funciones de coste o pérdida.
La verdadera forma de la función de pérdida sólo puede ser construída si se tuviesen datos infinitos. Al ser finita la cantidad de datos que se tiene, la función de pérdida obtenida no reflejará la verdadera forma de la función de pérdida.
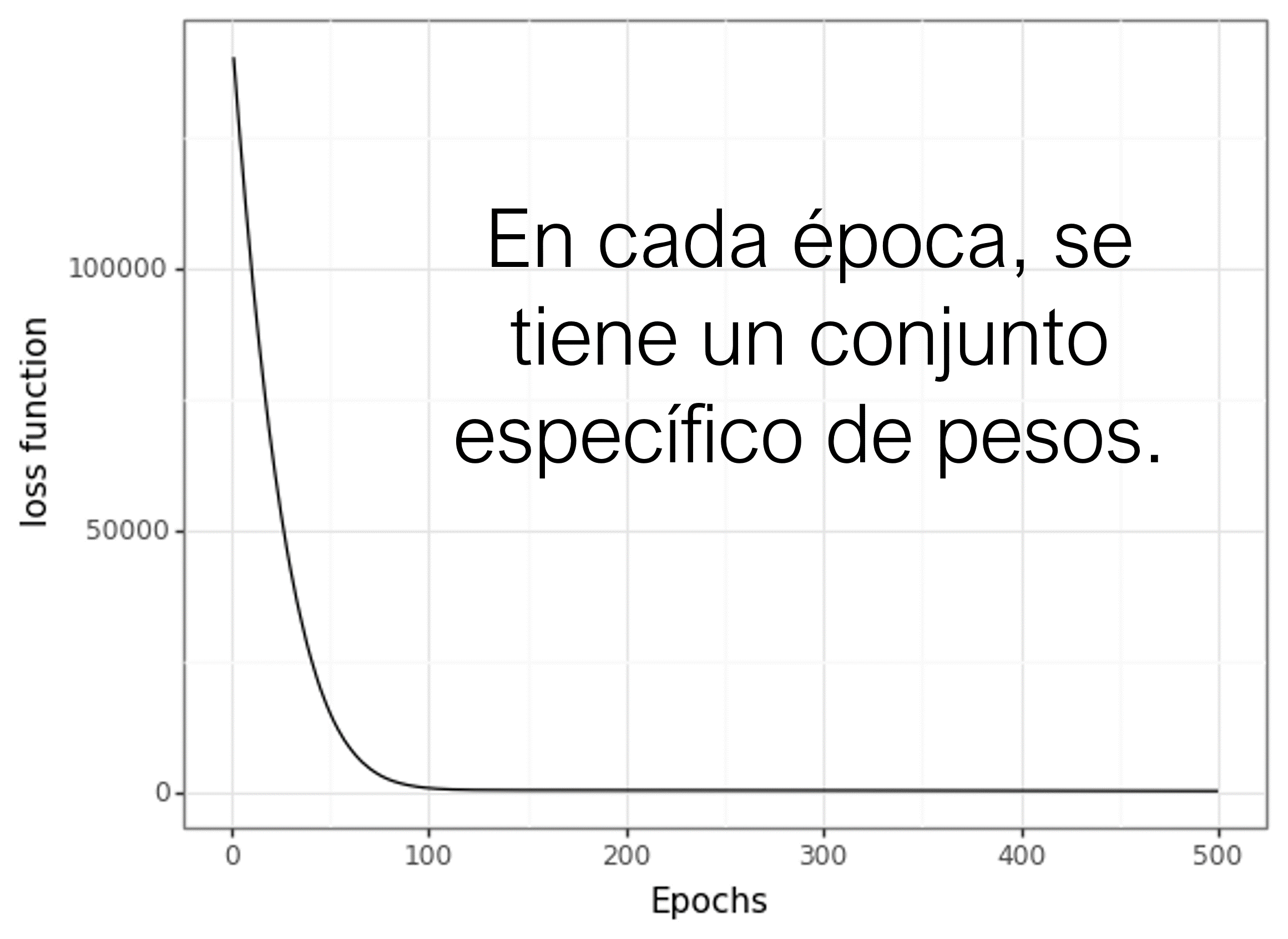
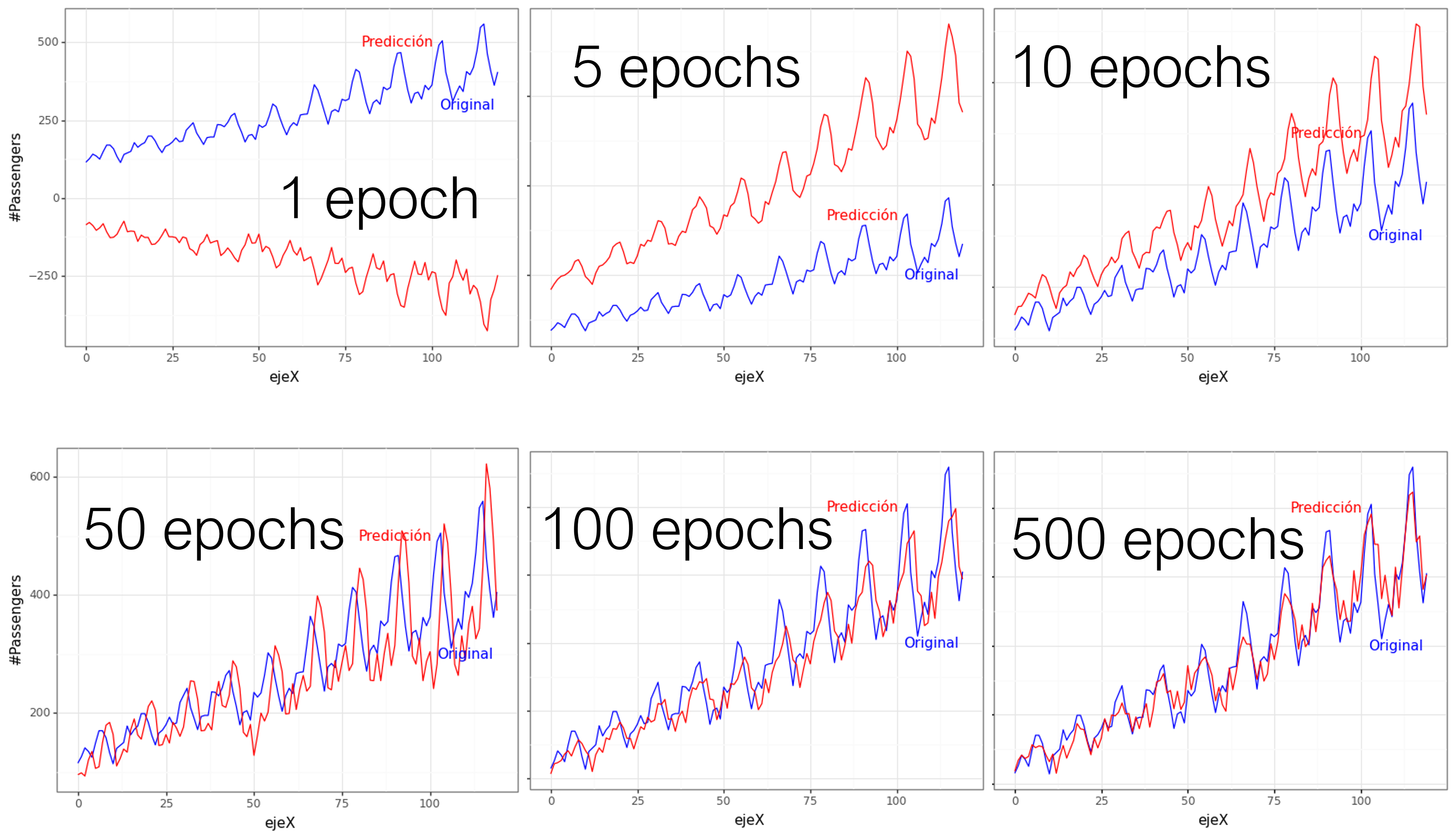
Resultados de predicción de un modelo a través de las épocas
6.2 Decenso del gradiente
El proceso de entrenamiento está basado en el algoritmo de optimización de decenso del gradiente (Gradient descent optimization algorithm). Es decir, los pesos de las neuronas son actualizados utilizando el gradiente de la función de pérdida
\[\overline{W}_{t+1} = \overline{W}_{t} - \alpha \bigtriangledown L\]
El gradiente de la función de pérdida describe la pendiente, es decir, la dirección que we debe utilizar para minimizar el error.
\(\alpha\) representa el parámetro de aprendizaje, y debemos configurarlo con cuidado.
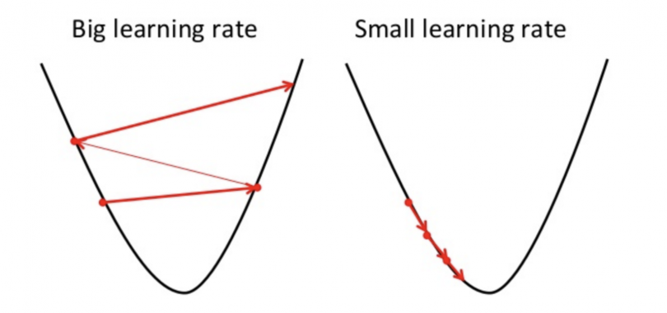
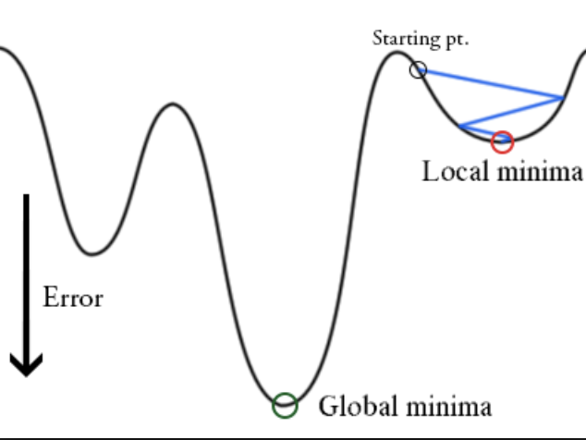
Se necesitan múltiples pasos porque sólo se calcula la dirección de la minimización, y esto no necesariamente indica el punto mínimo.
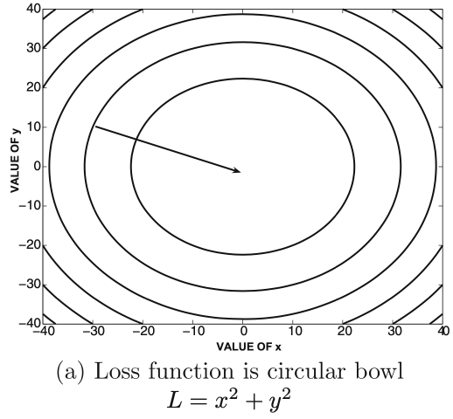
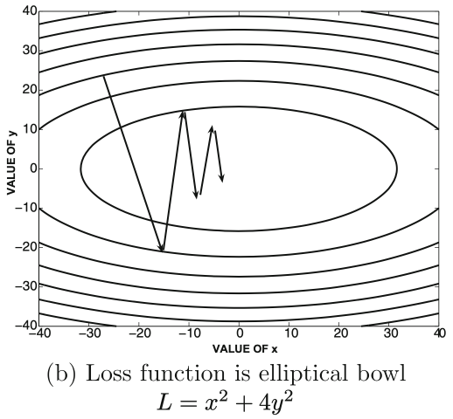
Volviendo al proceso intuitivo del entrenamiento que vimos anteriormente, ahora formalizando un poco:

6.3.1 Prepocesamiento de variables
A la hora de entrenar modelos basados en redes neuronales, y en general modelos de Deep Learning, es necesario aplicar a los datos, al menos, alguna de estas transformaciones:
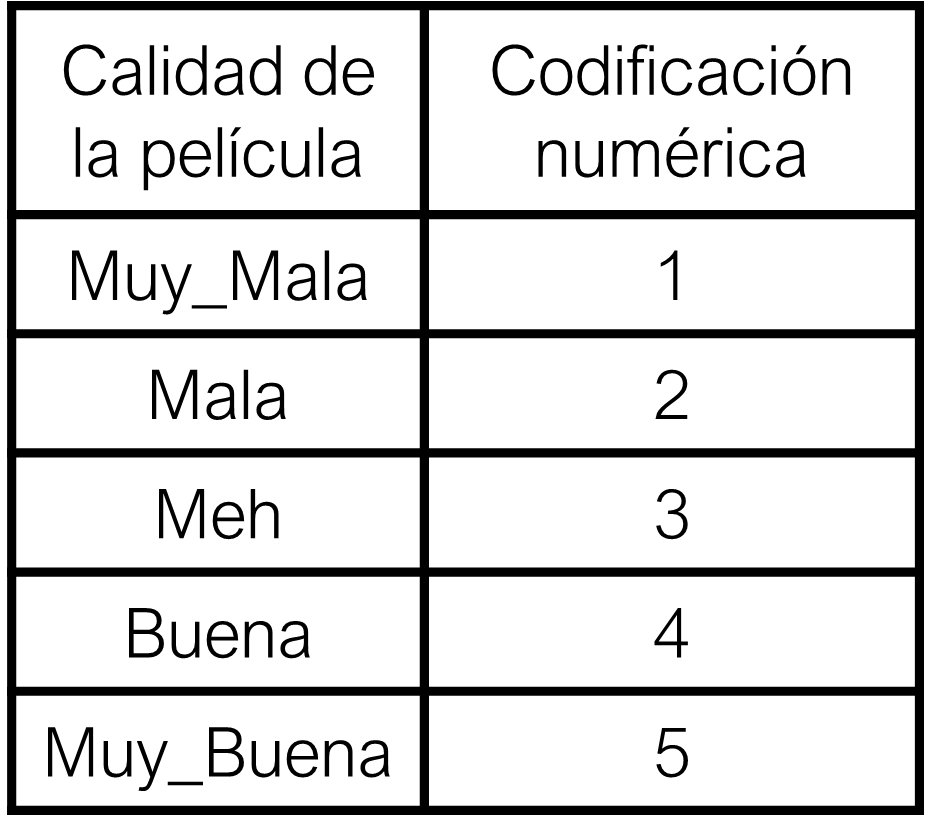
Codificación numérica (numerical encoding): Variables ordinales son codificadas en números enteros.
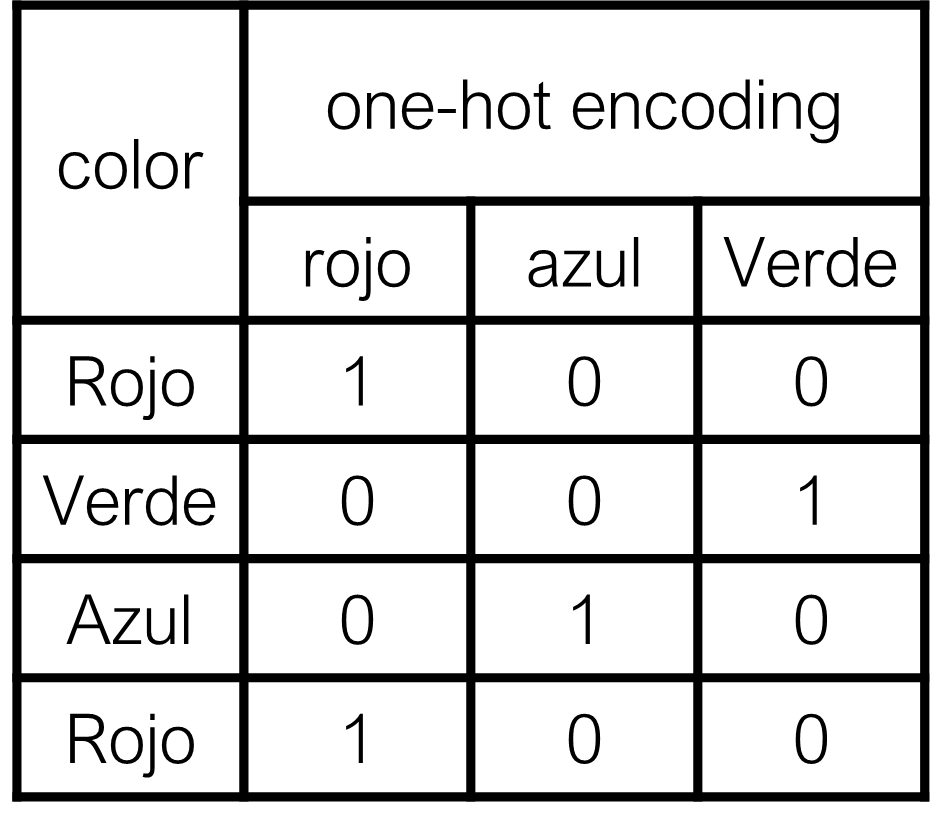
Binarización (one hot encoding) de las variables categóricas: La binarización consiste en crear nuevas variables dummy con cada uno de los niveles de las variables cualitativas. Este proceso es el mismo realizado en modelos lineales.
Estandarización y escalado de variables numéricas: Cuando los predictores son numéricos, la escala en la que se miden, así como la magnitud de su varianza pueden influir en gran medida en el modelo. Si no se igualan de alguna forma los predictores, aquellos que se midan en una escala mayor o que tengan más varianza dominarán el modelo aunque no sean los que más relación tienen con la variable respuesta. Para ello, en general centramos los datos, y estandarizamos o reescalamos entre 0 y 1.
Estandarización: \[ x_{std}^{(i)} = \frac{x^{(i)} - \mu_{x}}{\sigma_{x}} \]
Normalización (Min-Max Scaling): \[x_{norm}^{(i)} = \frac{x^{(i)} - \mathbf{x}_{min}}{\mathbf{x}_{max} - \mathbf{x}_{min}}\]
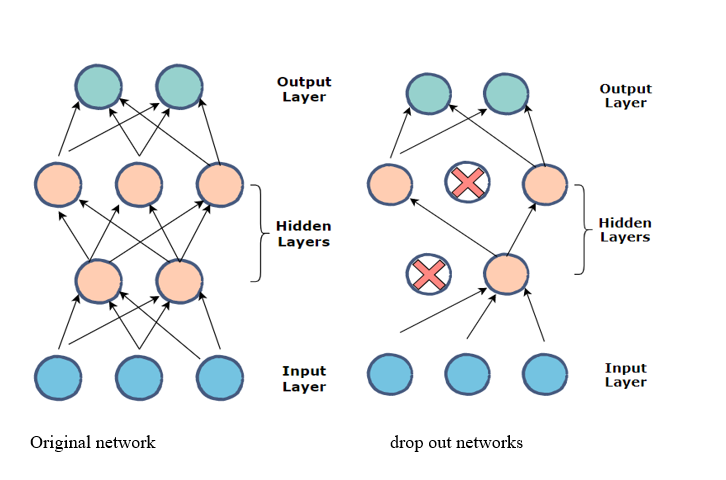
7.4.3 Dropout
El dropout es una técnica de regularización utilizada principalmente en redes neuronales. Durante el entrenamiento, algunas unidades (neuronas) se “apagan” aleatoriamente, es decir, se les asigna cero, lo que obliga a la red a aprender patrones redundantes que son útiles para la predicción y, por tanto, a ser menos sensible a pesos específicos de neuronas individuales.
Esta técnica ayuda a que la red se vuelva menos dependiente de cualquier camino único, y así mejora la generalización.
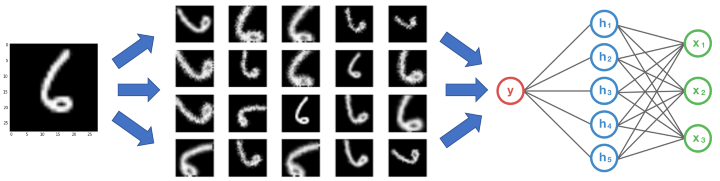
7.4.4 Aumento de Datos (Data Augmentation)
En el contexto de visión por computadora o procesamiento de lenguaje natural, la ampliación de datos implica generar datos de entrenamiento adicionales a partir de los datos existentes mediante la aplicación de una serie de transformaciones aleatorias que producen imágenes o textos plausiblemente reales.
Esto no solo expande el conjunto de entrenamiento sino que también ayuda a la red a aprender a ser invariante a estas transformaciones, lo que resulta en un modelo más robusto y generalizable.
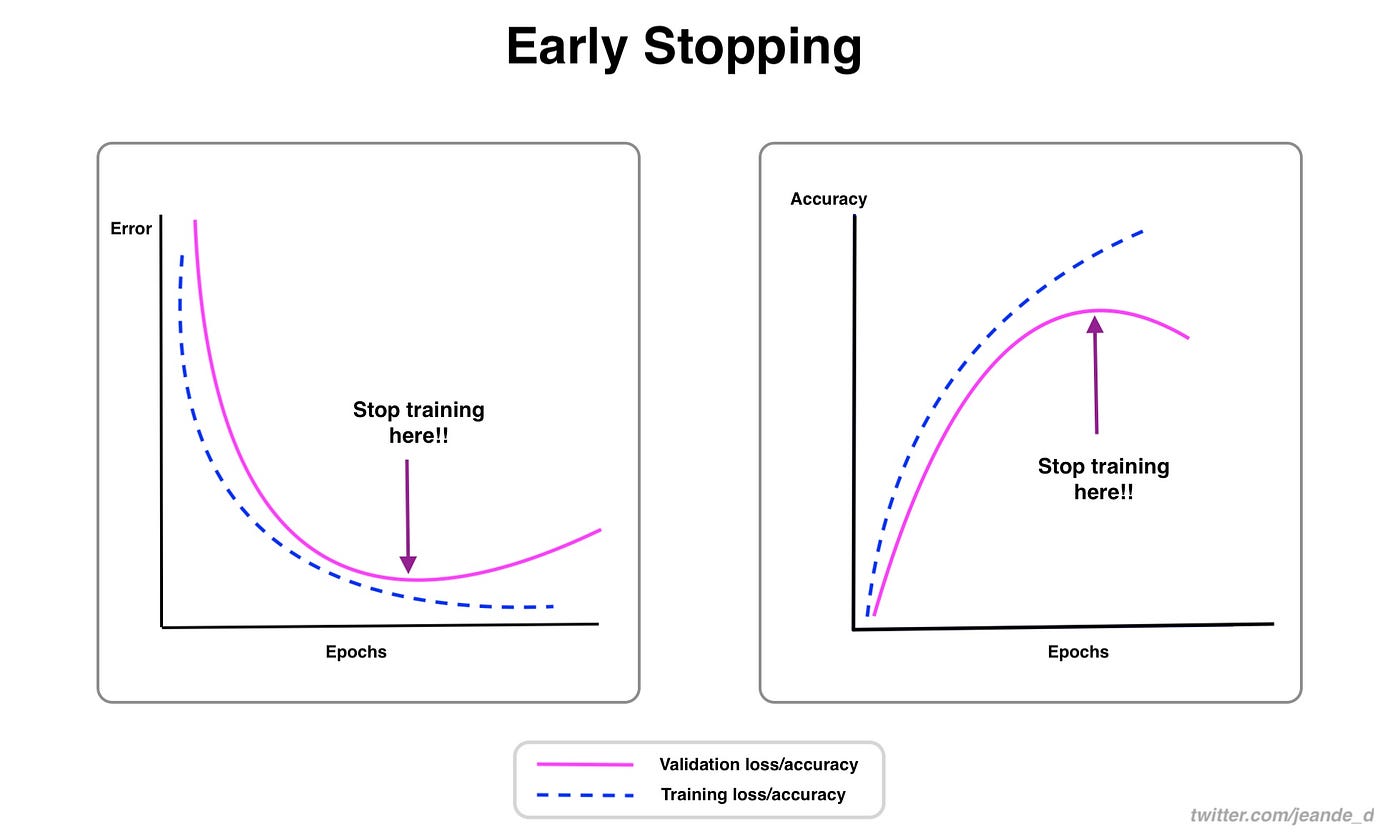
7.4.5 Detención Temprana (Early Stopping)
La detención temprana implica monitorear el rendimiento del modelo en un conjunto de validación separado durante el entrenamiento y detener el entrenamiento una vez que el rendimiento deje de mejorar.
Esto evita que el modelo continúe aprendiendo detalles del conjunto de entrenamiento que no se generalizan bien, lo que puede suceder si se entrena durante demasiado tiempo o con demasiados datos. Es una forma de regularización temporal ya que limita la cantidad de entrenamiento que recibe el modelo.
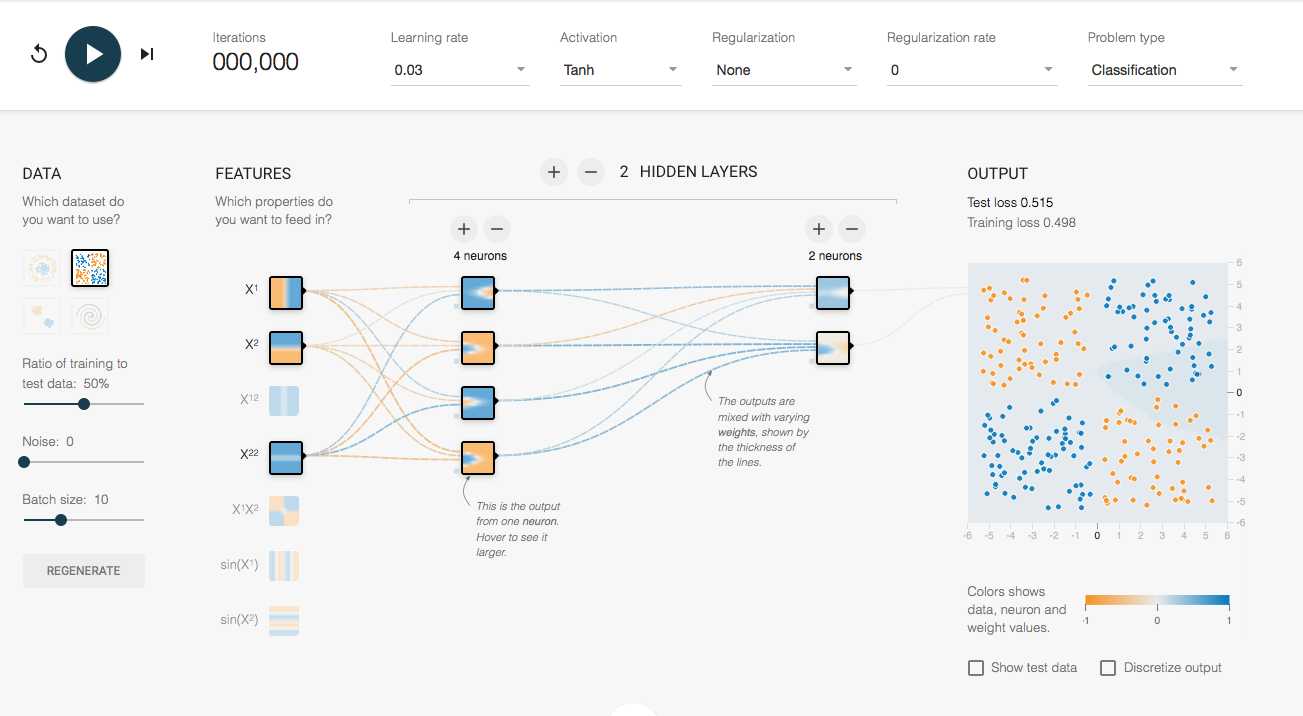
Playground Tensorflow es un sitio web que permite visualizar redes neuronales del tipo MLP
9 Referencias
