
Deep Learning
Unidad 3: Redes Neuronales Convolucionales (CNN)
1.2 Los bloques con los que se construyen las CNNs
Las CNNs son una familia de modelos que fueron originalmente inspirados por cómo funciona el cerebro humano al reconocer objetos.
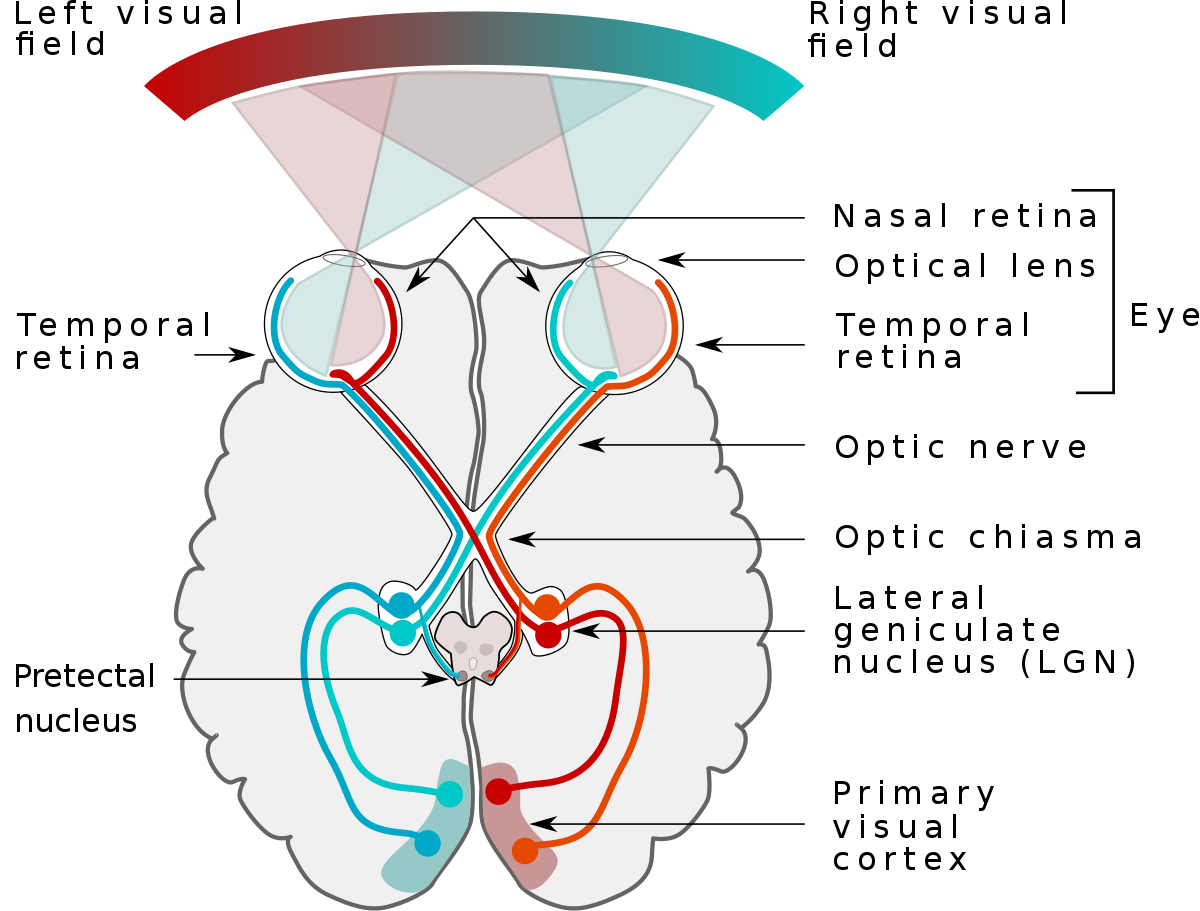
Esquema del sistema óptico humano
1.2.1 La corteza visual humana
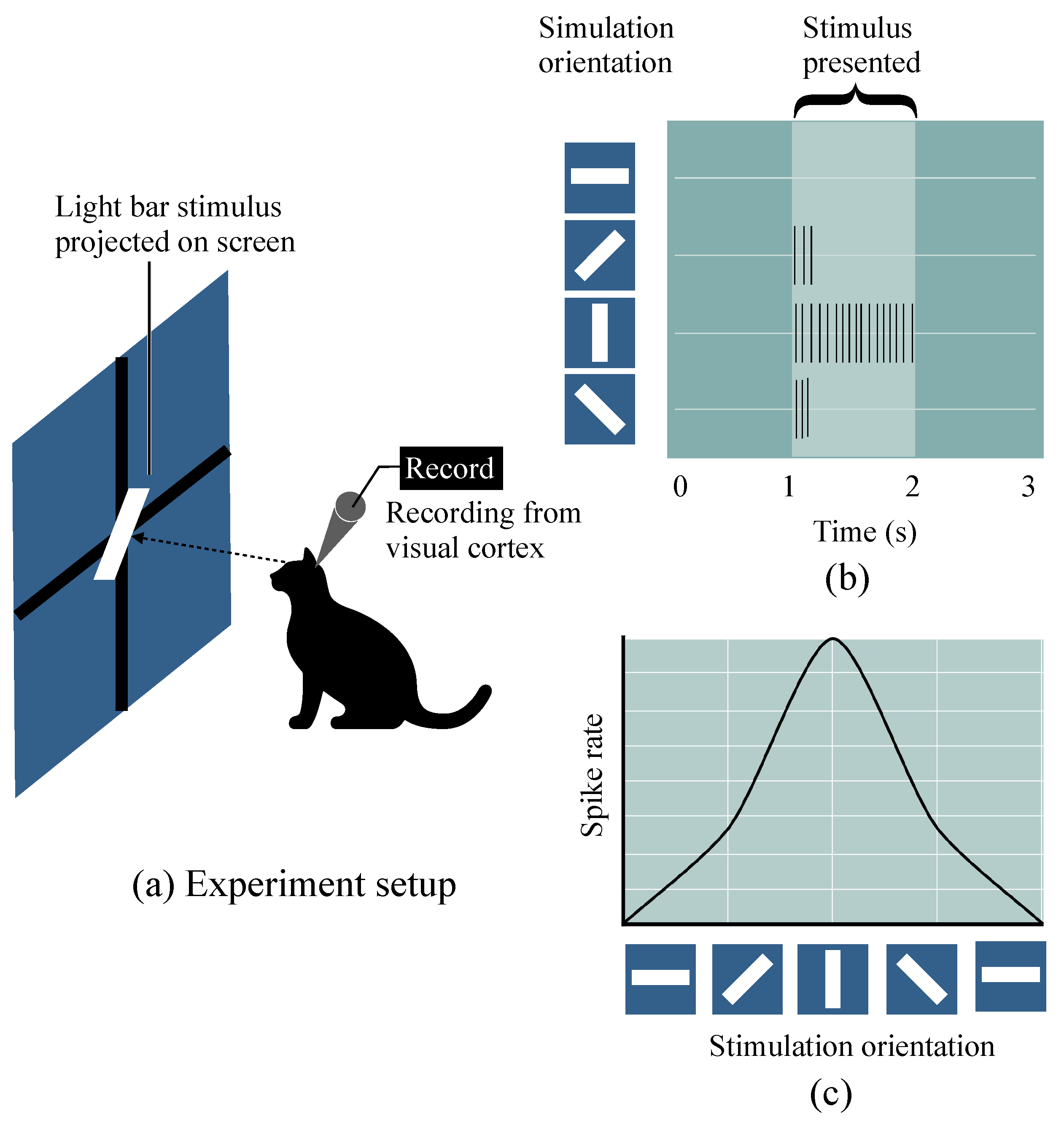
El descubrimiento original de cómo la corteza visual de nuestro cerebro funciona fue hecho por Hubel y Wiesel (1959), a través de la inserción de un microelectrodo en la corteza visual de un gato anestesiado.
Observaron que las neuronas cerebrales responden de forma diferente después de proyectar diferentes patrones de luz en frente del gato.
Esto eventualmente llevó al descubrimiento de las diferentes capas de la corteza visual.
Mientras que la capa primaria detecta principalmente bordes y líneas rectas, las capas superiores se enfocan más en extraer patrones y formas complejas.
1.2.2 Algo de historia
El desarrollo de las CNNs se remonta a los años 90, cuando Yann LeCun y sus colegas propusieron una nueva arquitectura de red neuronal para clasificar dígitos escritos a mano desde imágenes Handwritten Digit Recognition with a Back-Propagation Network (LeCun et al. 1989), publicado en la conferencia de Sistemas de Procesamiento de Información Neural (NeurIPS).
Debido al rendimiento sobresaliente de las CNNs para tareas de clasificación de imágenes, este tipo particular de red neuronal feedforward ganó mucha atención y condujo a mejoras tremendas en los sistemas de aprendizaje de máquinas en evolución.
Varios años más tarde, en 2019, Yann LeCun recibió el premio Turing (el premio más prestigioso en la ciencia de computadoras) por sus contribuciones al campo de la inteligencia artificial (IA), junto con otros investigadores, Yoshua Bengio y Geoffrey Hinton.

Ejemplo
Por ejemplo, si estamos tratando con imágenes, entonces las características de bajo nivel, como bordes y manchas, se extraen de las capas anteriores, las cuales se combinan para formar características de alto nivel. Estas características de alto nivel pueden formar formas más complejas, como los contornos generales de objetos como edificios, gatos o perros.
Una CNN calcula mapas de características de una imagen de entrada, donde cada elemento proviene de un parche local de píxeles en la imagen de entrada:

Típicamente, las CNNs están compuestas por varias capas convolucionales y de submuestreo (pooling) que son seguidas por una o más capas fully connected al final. Las capas fully connected son esencialmente un MLP, donde cada unidad de entrada, \(i\), está conectada a cada unidad de salida, \(j\), con un peso \(w_{ij}\).
Las capas de submuestreo (pooling), comúnmente conocidas como capas de agrupamiento (pooling layers), no tienen parámetros que se puedan aprender; por ejemplo, no hay unidades de peso o sesgo en las capas de pooling. Sin embargo, tanto las capas convolucionales como las fully connected tienen pesos y sesgos que son optimizados durante el entrenamiento.

Esquema de una CNN
En su forma general, la convolución es una operación sobre dos funciones con argumentos reales.

Supongamos que estamos rastreando la ubicación de una nave espacial con un sensor láser. Nuestro sensor láser nos entrega una sola salida \(x(t)\), la posición de la nave espacial en el tiempo \(t\), en donde \(x\) y \(t\) son valores reales.
Ahora supongamos que nuestro sensor laser es algo ruidoso. Para obtener una estimación menos ruidosa de la posición de la nave, podriamos promediar muchas mediciones, siendo las mediciones más recientes más relevantes, por lo que sería un promedio ponderado que otorga más peso a las observaciones más recientes.

Sparse connectivity

Parameter sharing
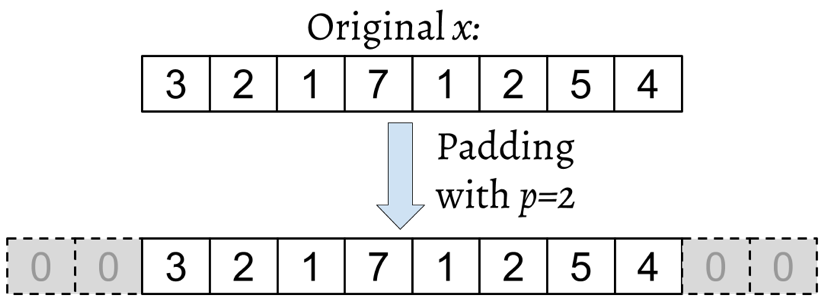
Este proceso se llama relleno de ceros o simplemente relleno (padding). Aquí, el número de ceros añadidos a cada lado se denota por \(p\). Un ejemplo de relleno para un vector unidimensional, \(x\), se muestra a continuación:
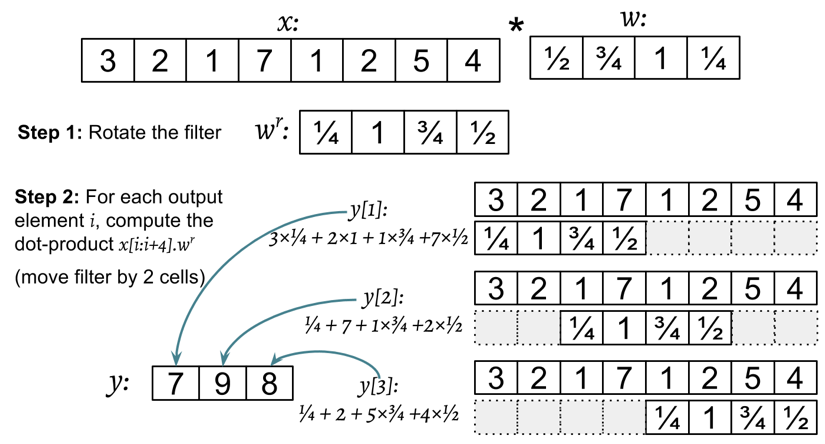
Entonces, el producto punto, \(x[i : i + m] \cdot w^r\), se calcula para obtener un elemento, \(y[i]\), donde \(x[i : i + m]\) es un segmento de \(x\) con tamaño \(m\).
Esta operación se repite como en un enfoque de ventana deslizante para obtener todos los elementos de salida.

Notar que, todas las técnicas mencionadas anteriormente, como el padding, rotar la matriz del filtro, y el uso de strides, también son aplicables a convoluciones en 2D, siempre y cuando se extiendan a ambas dimensiones de manera independiente. La figura siguiente demuestra la convolución en 2D de una matriz de entrada de tamaño \(6 \times 6\), utilizando un kernel de tamaño \(2 \times 2\). La matriz se rellena con ceros con \(p = 1\). Como resultado, la salida de la convolución en 2D tendrá un tamaño de \(4 \times 4\):
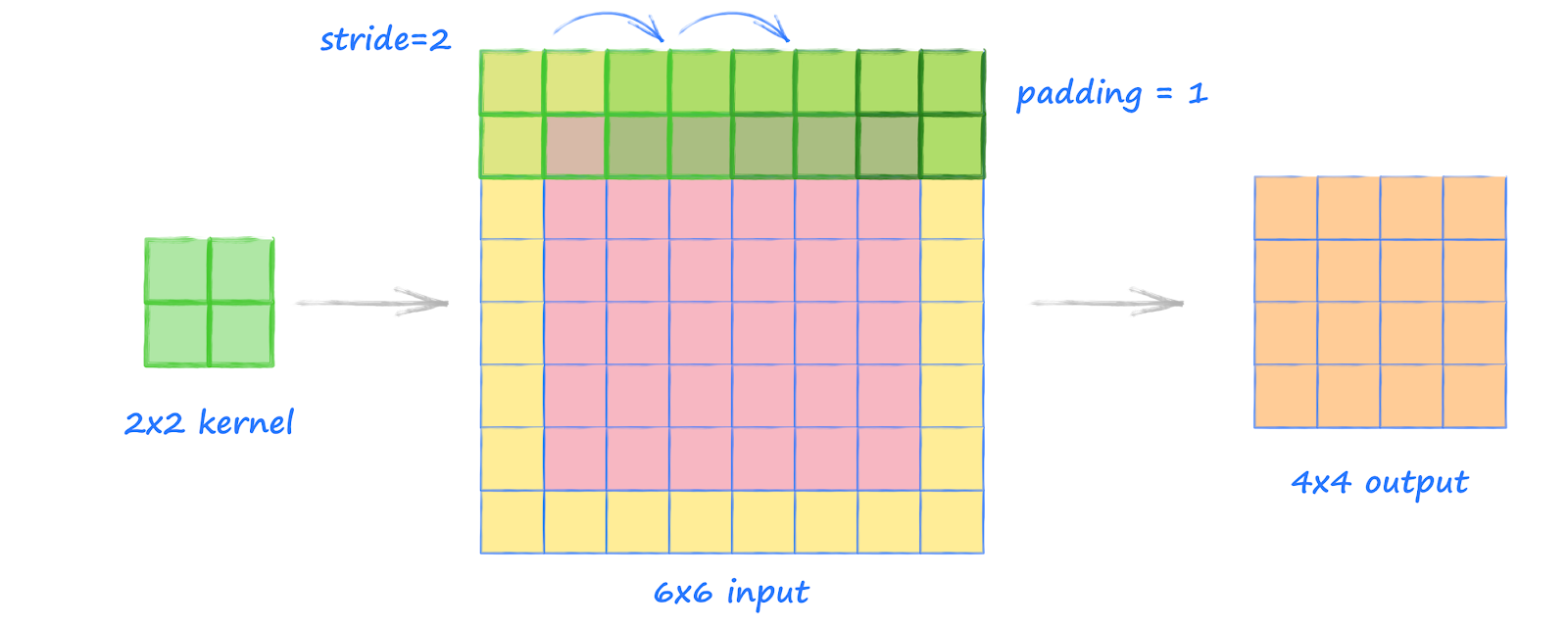
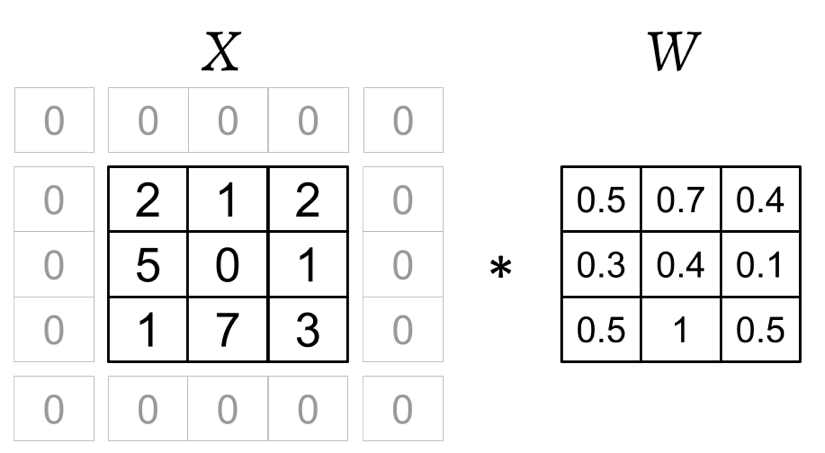
Acá se muestra una convolución 2D entre una matriz de entrada, \(X_{3 \times 3}\), y una matriz de núcleo, \(W_{3 \times 3}\), utilizando un padding \(p = (1, 1)\) y un stride \(s = (2, 2)\). De acuerdo al padding especificado, se añade una capa de ceros en cada lado de la matriz de entrada, lo que resulta en la matriz con padding \(X_{padded}\) de \(5 \times 5\), de la siguiente manera:
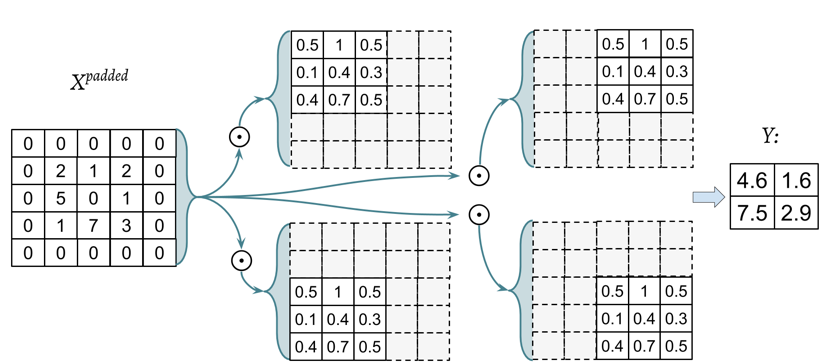
El código anterior crea primero la matriz \(W\) y luego utiliza la indexación para invertir tanto las filas como las columnas. A continuación, podemos desplazar la matriz de filtro rotado a lo largo de la matriz de entrada con padding, \(X_{\text{padded}}\), como una ventana deslizante y calcular la suma del producto elemento a elemento, que es denotado por el operador \(\odot\) en la figura siguiente:
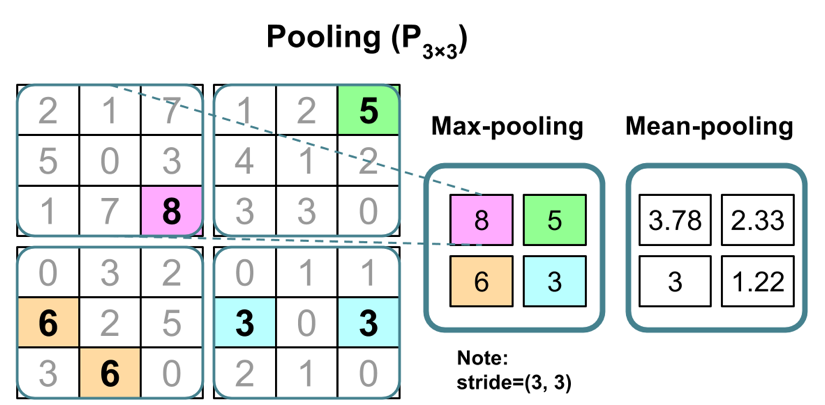
El submuestreo se aplica típicamente en dos formas de operaciones de pooling en las CNNs: max-pooling y mean-pooling (también conocido como average-pooling).
La capa de pooling se denota generalmente por \(P_{n1 \times n2}\). Aquí, el subíndice determina el tamaño del vecindario (el número de píxeles adyacentes en cada dimensión) donde se realiza la operación de máximo o promedio. Nos referimos a tal vecindario como el tamaño de pooling.
La operación se describe en la siguiente figura. Aquí, max-pooling toma el valor máximo de un vecindario de píxeles, y mean-pooling calcula su promedio:
5.1 Múltiples entradas y canales de color
Una entrada a una capa convolucional puede contener uno o más arreglos o matrices 2D con dimensiones \(N_1 \times N_2\) (por ejemplo, la altura y ancho de la imagen en píxeles).
Estas matrices \(N_1 \times N_2\) se llaman canales. Las implementaciones convencionales de capas convolucionales esperan una representación tensorial de rango 3 como entrada, por ejemplo, un arreglo tridimensional, \(X_{N_1 \times N_2 \times C_{in}}\), donde \(C_{in}\) es el número de canales de entrada.
-
Por ejemplo, consideremos imágenes como entrada a la primera capa de una CNN.
Si la imagen es a color y usa el modo de color RGB, entonces \(C_{in} = 3\) (para los canales de color rojo, verde y azul en RGB).
Si la imagen es en escala de grises, entonces tenemos \(C_{in} = 1\), porque solo hay un canal con los valores de intensidad de píxeles en escala de grises.

En este ejemplo, hay tres canales de entrada.
El tensor del kernel es cuatridimensional. Cada matriz de kernel está denotada como \(m_1 \times m_2\) y hay tres de ellas, una para cada canal de entrada.
Además, hay cinco de esos kernels, contabilizando cinco mapas de características de salida.
Finalmente, hay una capa de pooling para submuestrear los mapas de características.

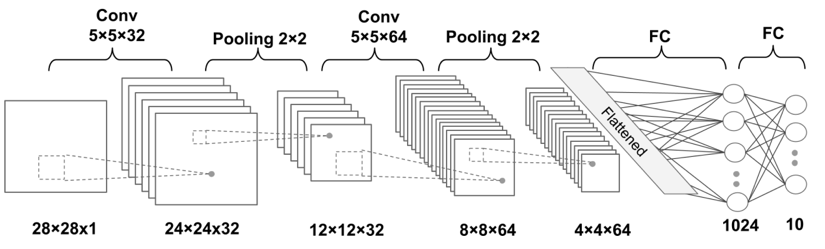
5.2 Multi-Layer CNN
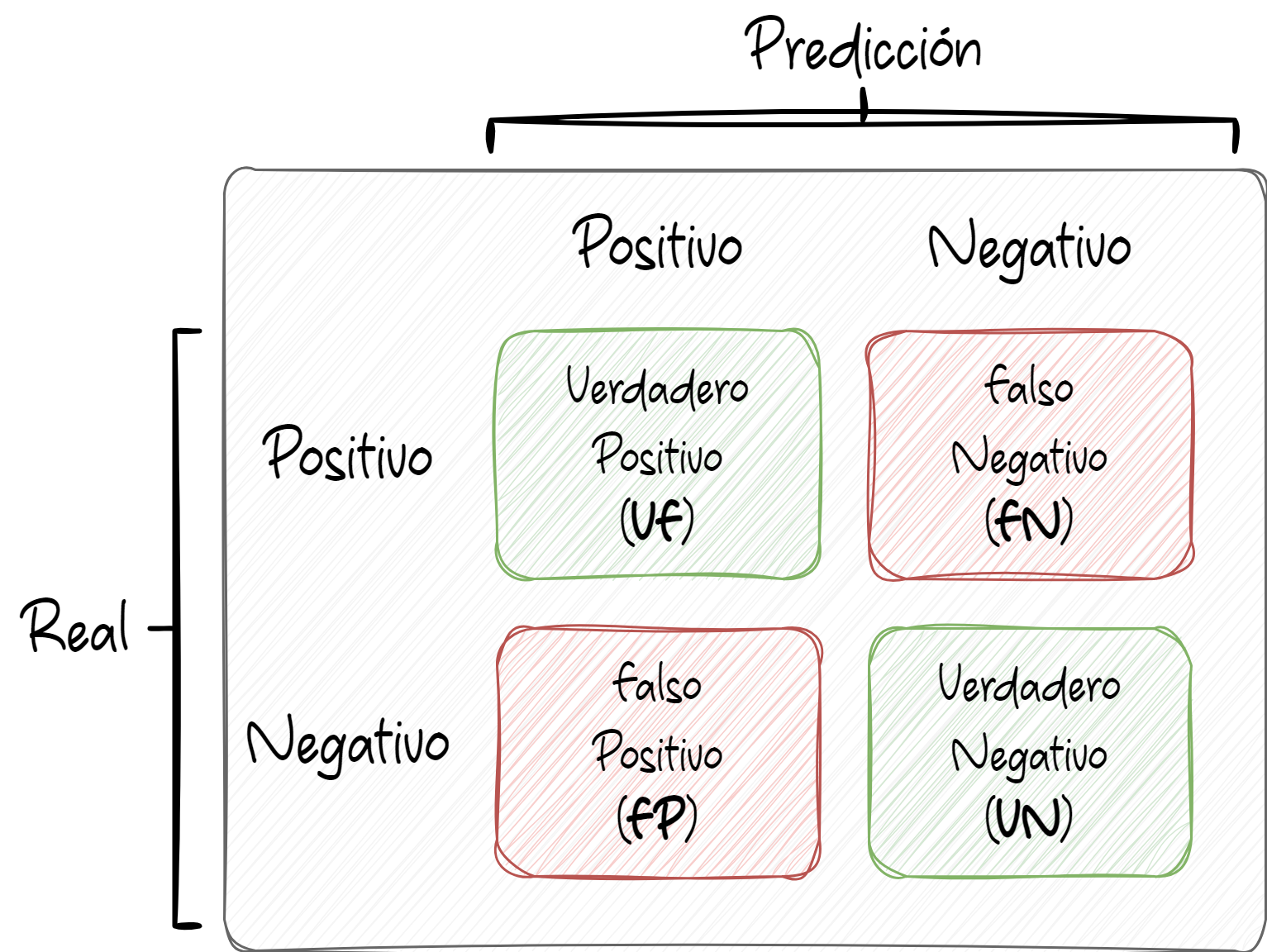
Esquema de una matriz de confusión para clasificación binaria
7.1 CNNs más famosas
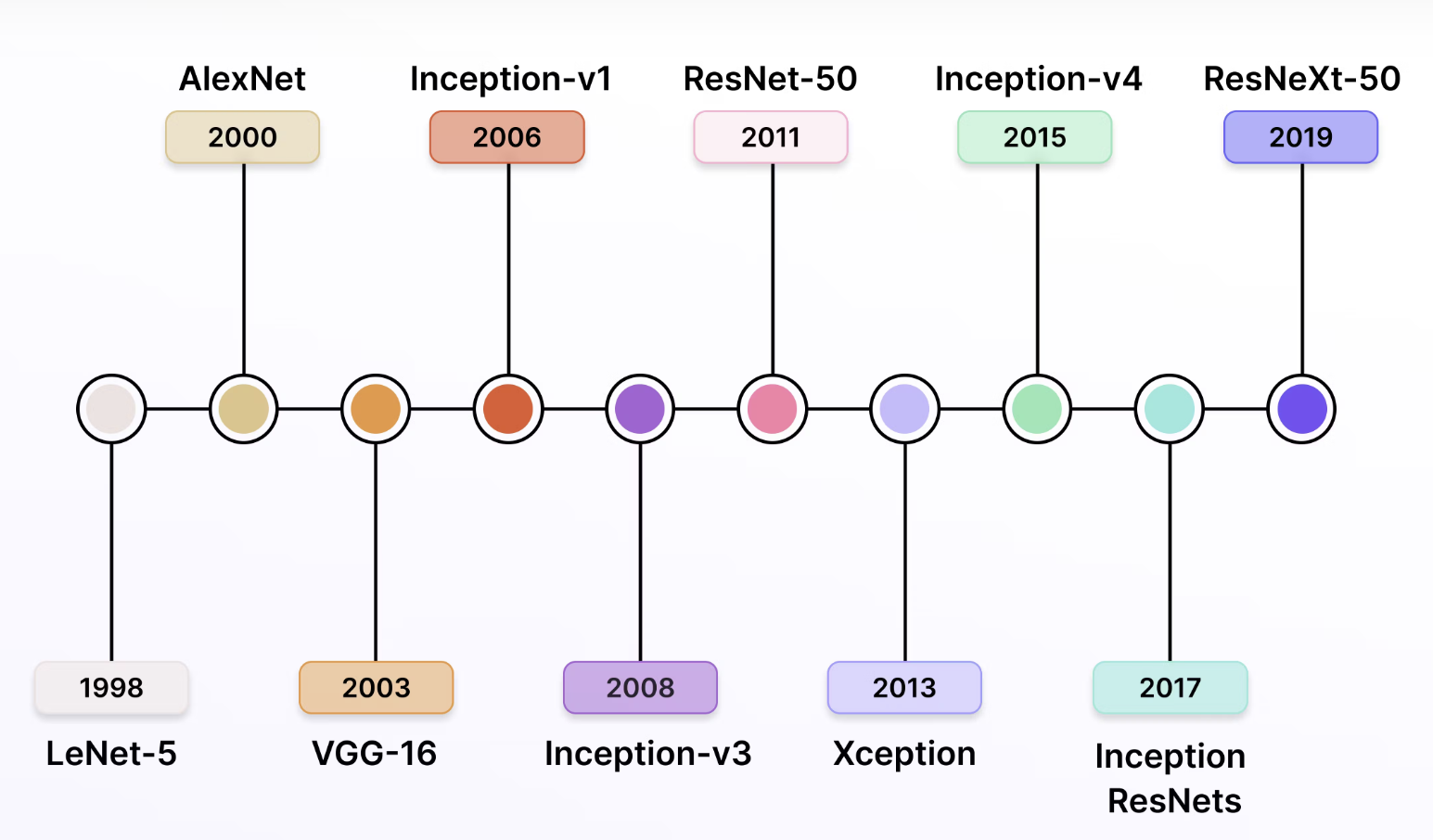
Línea de tiempo (hasta 2019) de las CNNs y su desarrollo
7.2 LeNet-5
LeNet-5 es una de las primeras arquitecturas de redes neuronales convolucionales, desarrollada por Yann LeCun en 1998. Fue diseñada para reconocer caracteres escritos a mano y se compone de dos capas convolucionales seguidas de capas de agrupamiento y capas completamente conectadas.

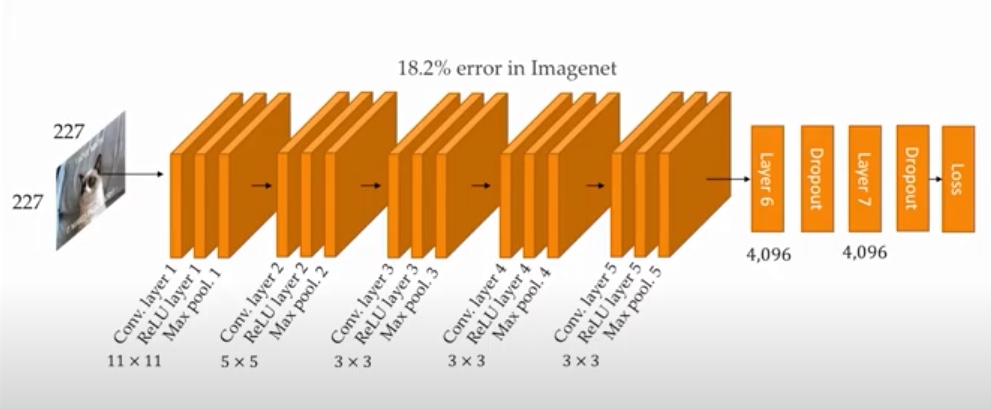
7.3 AlexNet
AlexNet, desarrollada por Alex Krizhevsky y su equipo en 2012, es una red profunda que ganó la competencia ImageNet. Introdujo el uso de ReLU como función de activación y popularizó el uso de GPU para entrenamiento.
7.4 GoogleNet (Inception)
GoogleNet, también conocida como Inception v1, fue desarrollada por Google y ganó la competencia ImageNet en 2014. Introduce los módulos de Inception que permiten diferentes tamaños de convoluciones en la misma capa.

7.5 VGG16
VGG16, creada por el Visual Geometry Group de la Universidad de Oxford en 2014, es conocida por su simplicidad y profundidad, usando solo convoluciones 3x3 y max-pooling. Esta arquitectura es efectiva y fácil de implementar.
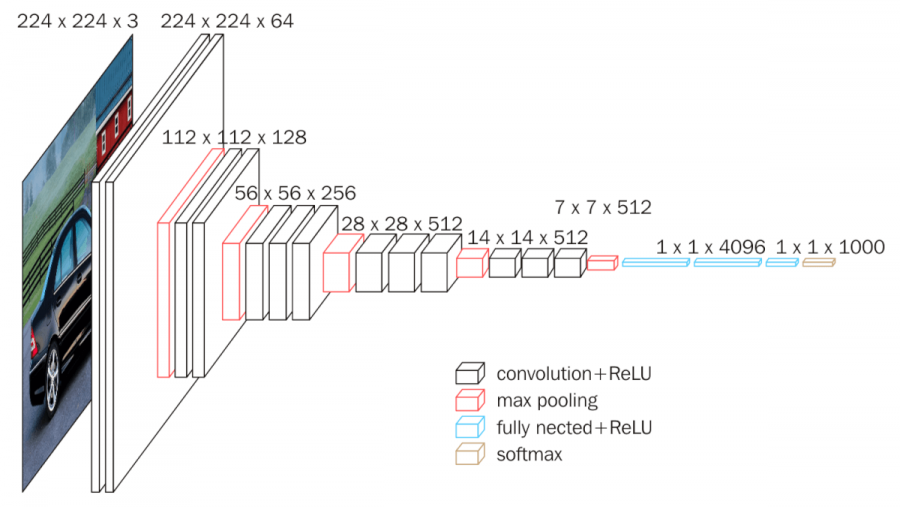
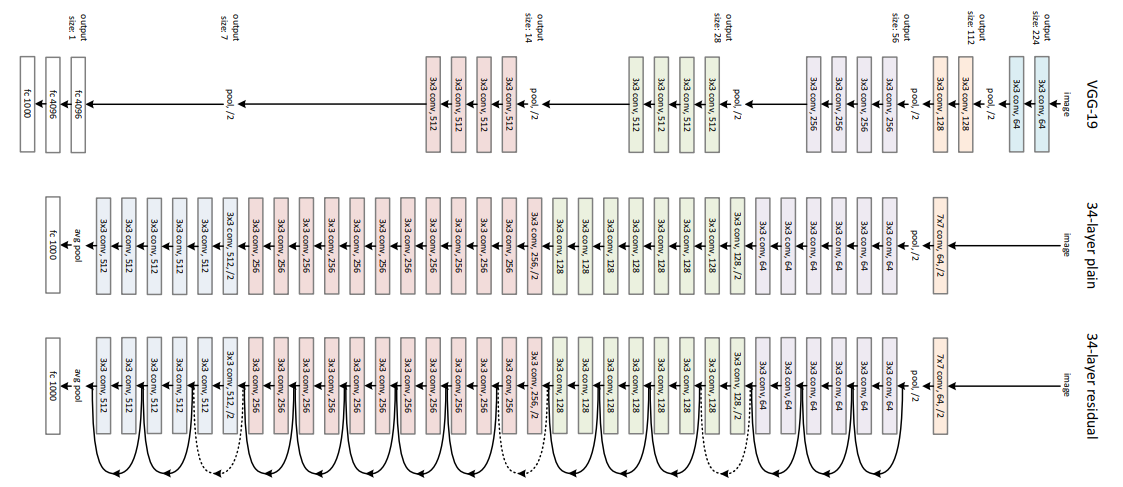
7.6 ResNet
ResNet (Redes Residuales), introducida por Microsoft en 2015, es una arquitectura profunda que utiliza “bloques residuales” para permitir la construcción de redes muy profundas sin el problema de la desaparición del gradiente.
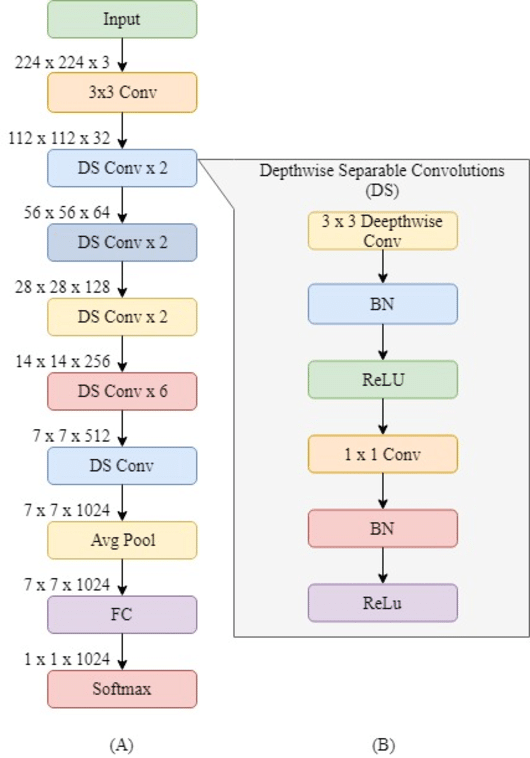
7.7 MobileNet
MobileNet, desarrollada por Google, está optimizada para dispositivos móviles y embebidos. Utiliza separable depthwise convolutions para reducir la cantidad de parámetros y cálculos.
8 Referencias
Hubel, David H, y Torsten N Wiesel. 1959. «Receptive fields of single neurones in the cat’s striate cortex». The Journal of physiology 148 (3): 574.
LeCun, Yann, Bernhard Boser, John Denker, Donnie Henderson, Richard Howard, Wayne Hubbard, y Lawrence Jackel. 1989. «Handwritten digit recognition with a back-propagation network». Advances in neural information processing systems 2.
Li, Bin, Yuki Todo, y Zheng Tang. 2022. «Artificial Visual System for Orientation Detection Based on Hubel–Wiesel Model». Brain Sciences 12 (4): 470.
