Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 6.4 2.8 5.6 2.2 virginica
2 5.2 4.1 1.5 0.1 setosa
3 6.5 3.0 5.5 1.8 virginica
4 6.1 2.9 4.7 1.4 versicolor
5 5.6 2.5 3.9 1.1 versicolor
6 5.0 2.0 3.5 1.0 versicolor
7 4.4 3.2 1.3 0.2 setosa
8 4.5 2.3 1.3 0.3 setosa
9 6.7 3.0 5.0 1.7 versicolor
10 7.2 3.6 6.1 2.5 virginicaDeep Learning
Unidad 4: Redes Neuronales Recurrentes (RNNs)
1.2 ¿Qué son los datos secuenciales?
Datos secuenciales
Conjunto de observaciones recopiladas y ordenadas en función de un criterio temporal, espacial, o de cualquier otra dimensión en la que el orden de las observaciones sea esencial para su análisis.
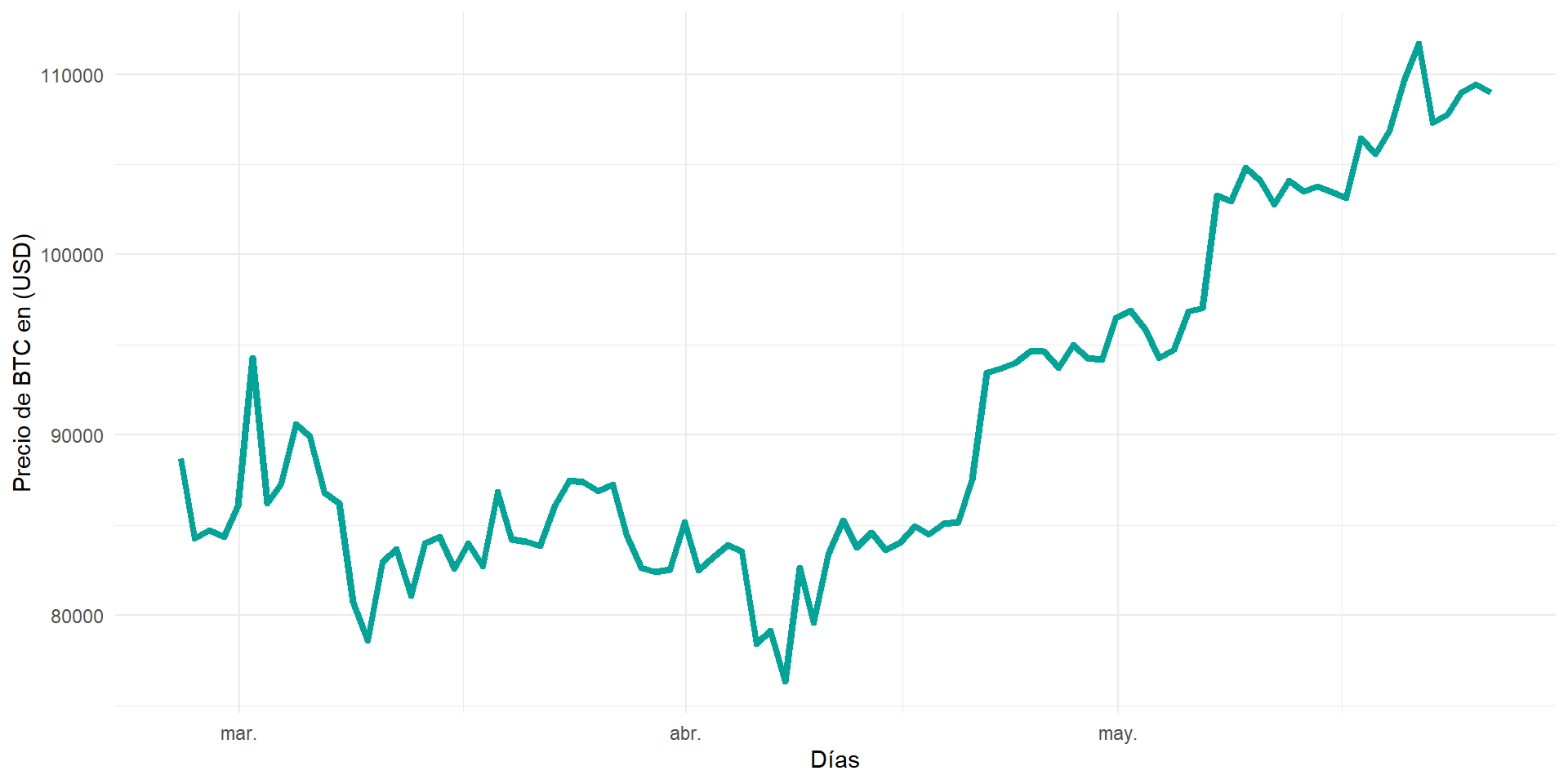
library(cryptoQuotes)
library(xts)
library(tidyverse)
BTC <- get_quote(
ticker = "BTCUSDT",
source = "binance",
futures = FALSE,
interval = "1d",
from = Sys.Date() - 90
)
data.frame(date = index(BTC),
BTC = BTC$close) %>%
mutate(date = as.POSIXct(date)) %>%
ggplot()+
geom_line(aes(x=date, y=close), color="#00a499", linewidth=1.5) +
ylab("Precio de BTC en (USD)") + xlab("Días") +
theme_minimal()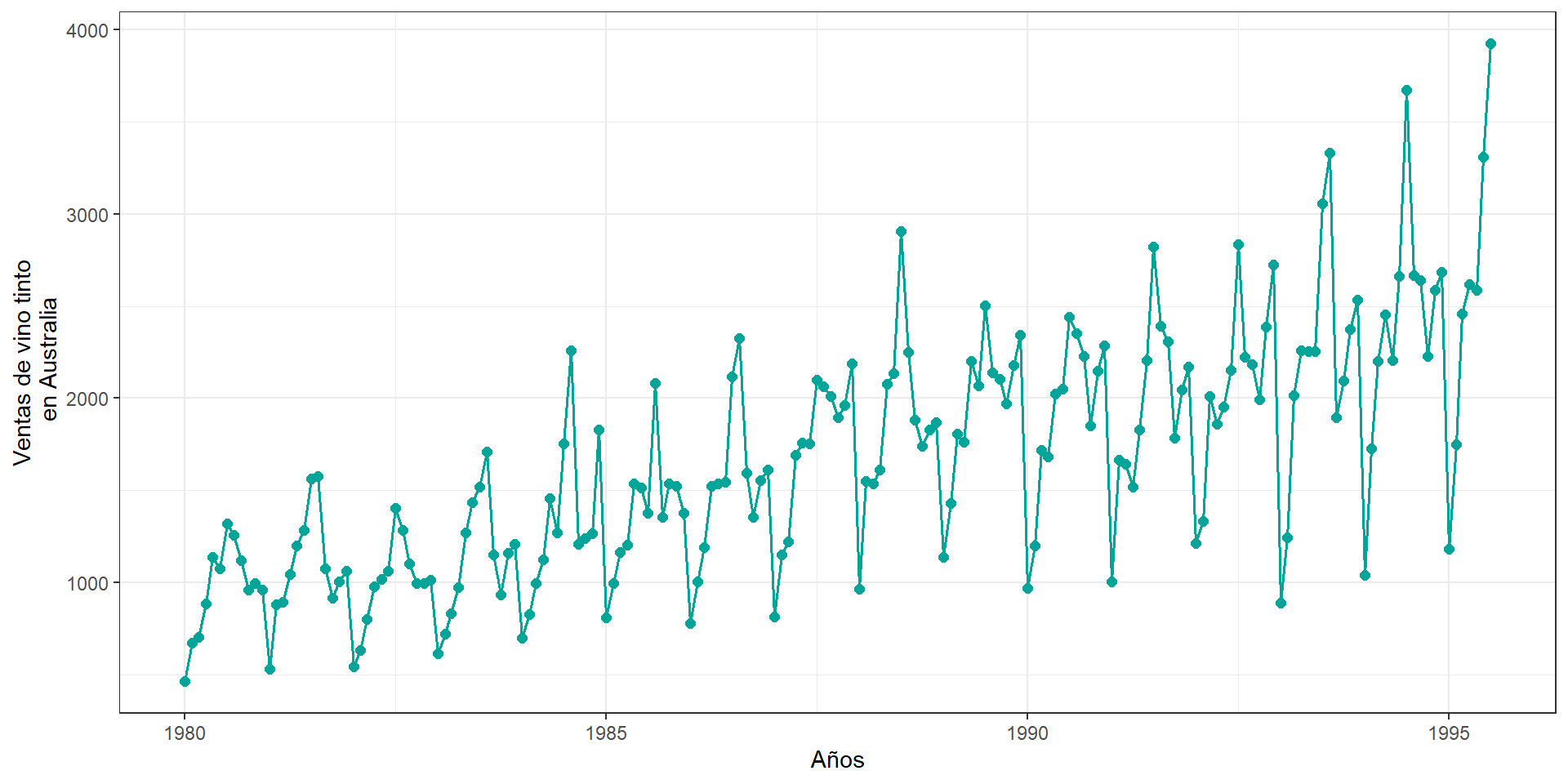

library(tidyverse)
library(ggplot2)
library(readr)
# Vino ----
# URL de los datos
url <- "https://raw.githubusercontent.com/rajansharm/Time-Series-Analysis/refs/heads/master/AusWineSales.csv"
# Leer los datos desde el enlace
wine_data <- read_csv(url)
# Convertir el campo 'YearMonth' a formato de fecha
wine_data$YearMonth <- as.Date(paste0(wine_data$YearMonth, "-01"))
# Crear el gráfico
wine =
ggplot(wine_data, aes(x = YearMonth, y = Red)) +
geom_line(color = "#00a499", linewidth = 0.7) +
geom_point(color = "#00a499", size = 2) +
labs(
x = "Años",
y = "Ventas de vino tinto\n en Australia"
) +
theme_bw()library(tidyverse)
library(ggplot2)
library(readr)
library(zoo)
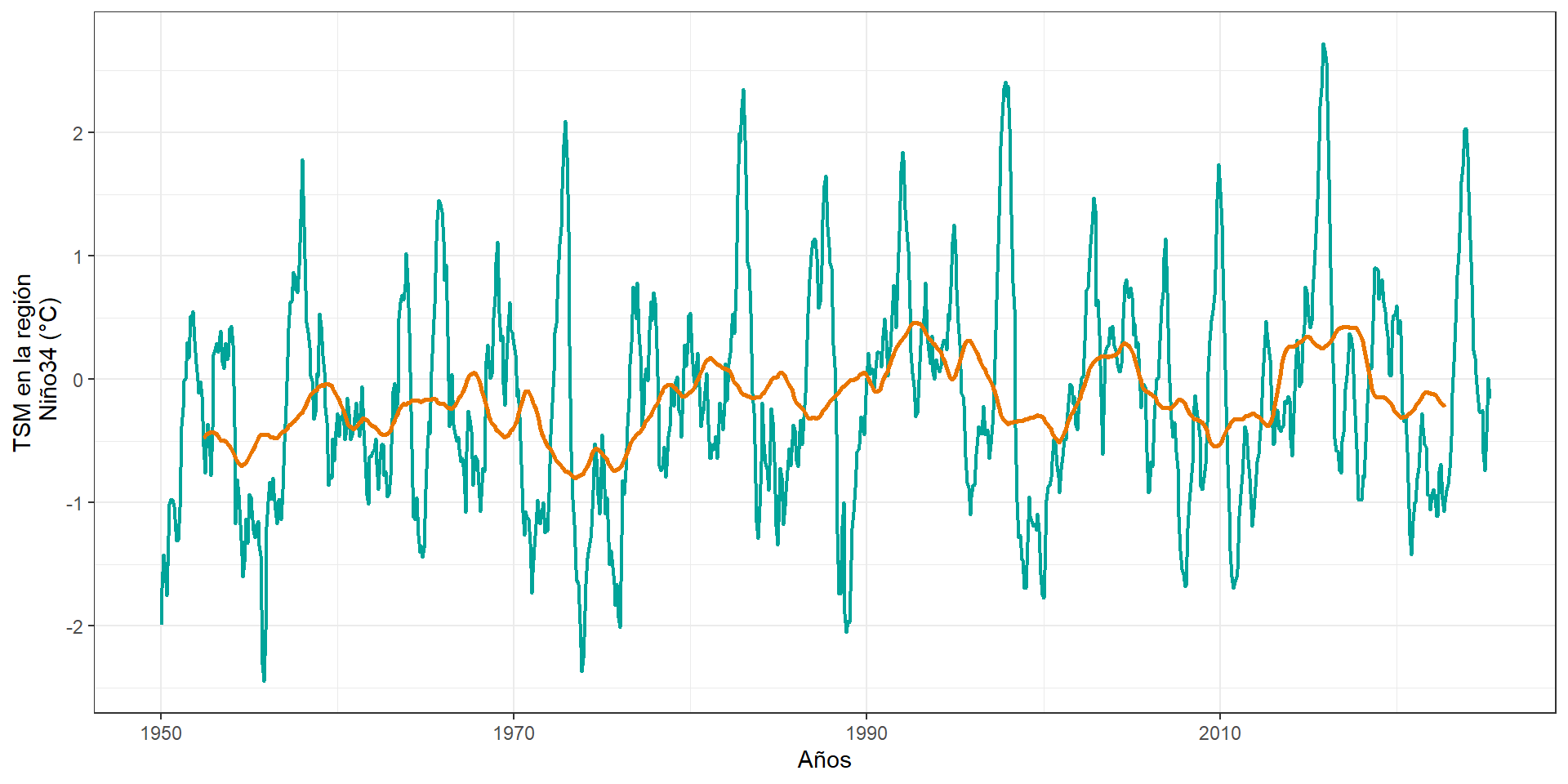
# SST ----
url <- "https://psl.noaa.gov/data/correlation/nina34.anom.data"
data_raw <- read_lines(url)
data_lines <- data_raw %>%
.[-1] %>% # Eliminar automáticamente la primera línea
.[str_detect(., "^[ ]*[0-9]{4}")] # Mantener líneas que comienzan con un año de 4 dígitos
# Convertir las líneas en un data frame procesable
data <- data_lines %>%
str_trim() %>%
str_split("\\s+", simplify = TRUE) %>%
as.data.frame(stringsAsFactors = FALSE) %>%
set_names(c("Year", paste0("Month_", 1:12))) %>%
mutate(across(everything(), as.numeric)) %>%
pivot_longer(cols = starts_with("Month_"), names_to = "Month", values_to = "Temperature") %>%
mutate(Month = as.numeric(str_remove(Month, "Month_")),
Time = Year + (Month - 1) / 12) %>%
filter(Temperature > -99)
# Calcular la media móvil de 5 años
data <- data %>%
arrange(Time) %>%
mutate(Moving_Avg = rollmean(Temperature, k = 60, fill = NA, align = "center")) # 5 años * 12 meses = 60
# Crear la gráfica
sst = ggplot(data, aes(x = Time)) +
geom_line(aes(y = Temperature), color = "#00a499", alpha = 1, size = 0.8) +
geom_line(aes(y = Moving_Avg), color = "#ea7600", size = 1) + # Línea de tendencia
labs(
x = "Años",
y = "TSM en la región\n Niño34 (°C)"
) +
theme_bw()library(tidyverse)
library(ggplot2)
library(latex2exp)
# Continua 1 ----
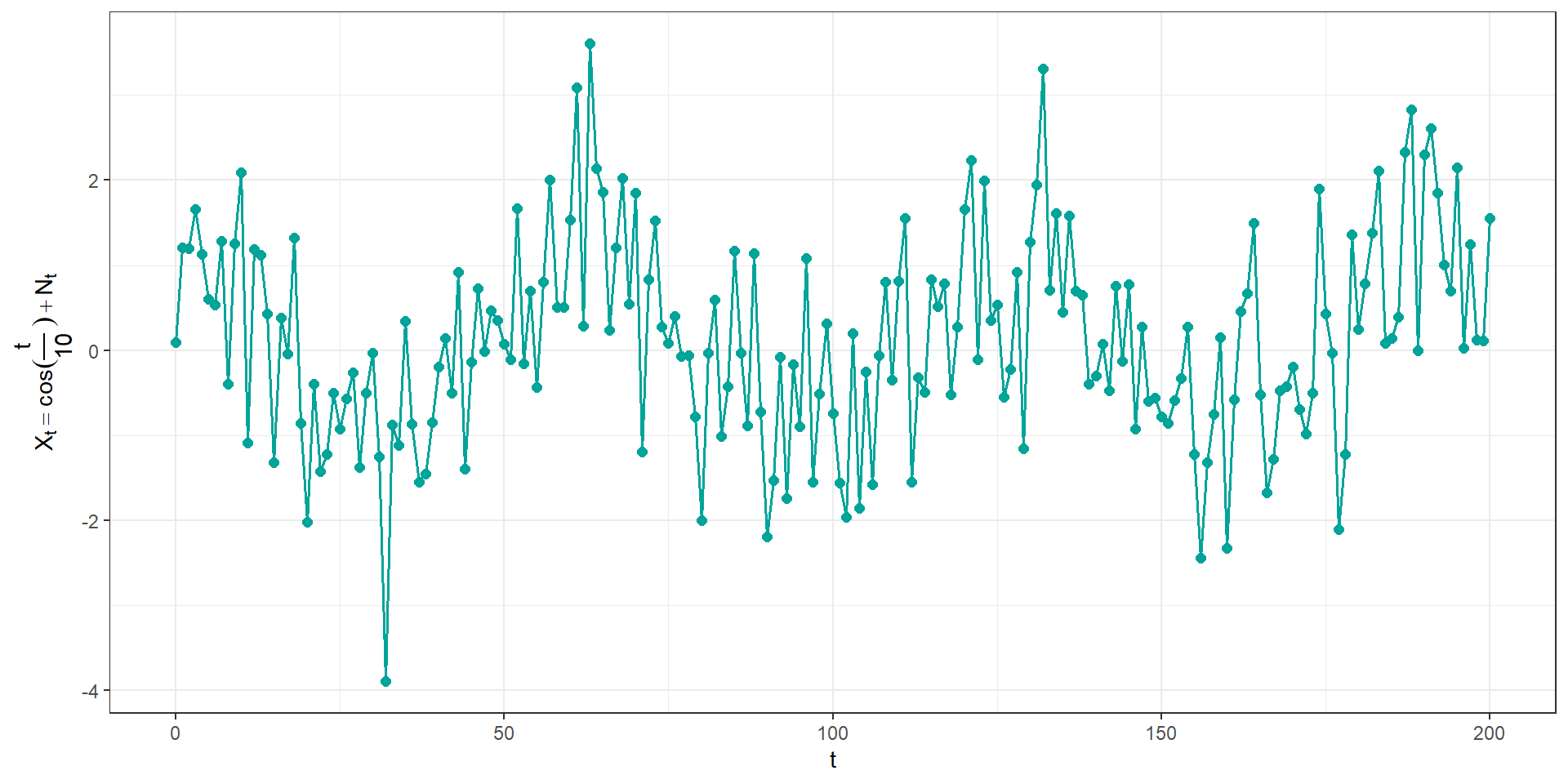
cont1 = data.frame(t = seq(0,200)) %>%
mutate(N = rnorm(length(t)),
x = cos(t/10) + N) %>%
ggplot(aes(x = t, y=x)) +
geom_line(color = "#00a499", linewidth = 0.7) +
geom_point(color = "#00a499", size = 2) +
xlab(TeX("t")) +
ylab(TeX("$X_t = cos(\\frac{t}{10})+N_t")) +
theme_bw()
# Continua 2 ----
cont2 = data.frame(t = seq(0,100)) %>%
mutate(x = cos(0.2*t + pi/3)) %>%
ggplot(aes(x = t, y=x)) +
geom_line(color = "#00a499", linewidth = 0.7) +
geom_point(color = "#00a499", size = 2) +
xlab(TeX("t")) +
ylab(TeX("$X_t = cos(0.2t + \\frac{\\pi}{3})")) +
theme_bw()1.5 Representando secuencias
A partir de las definiciones de Raschka y Mirjalili (2019)

1.6 Categorías en la modelación de secuencias
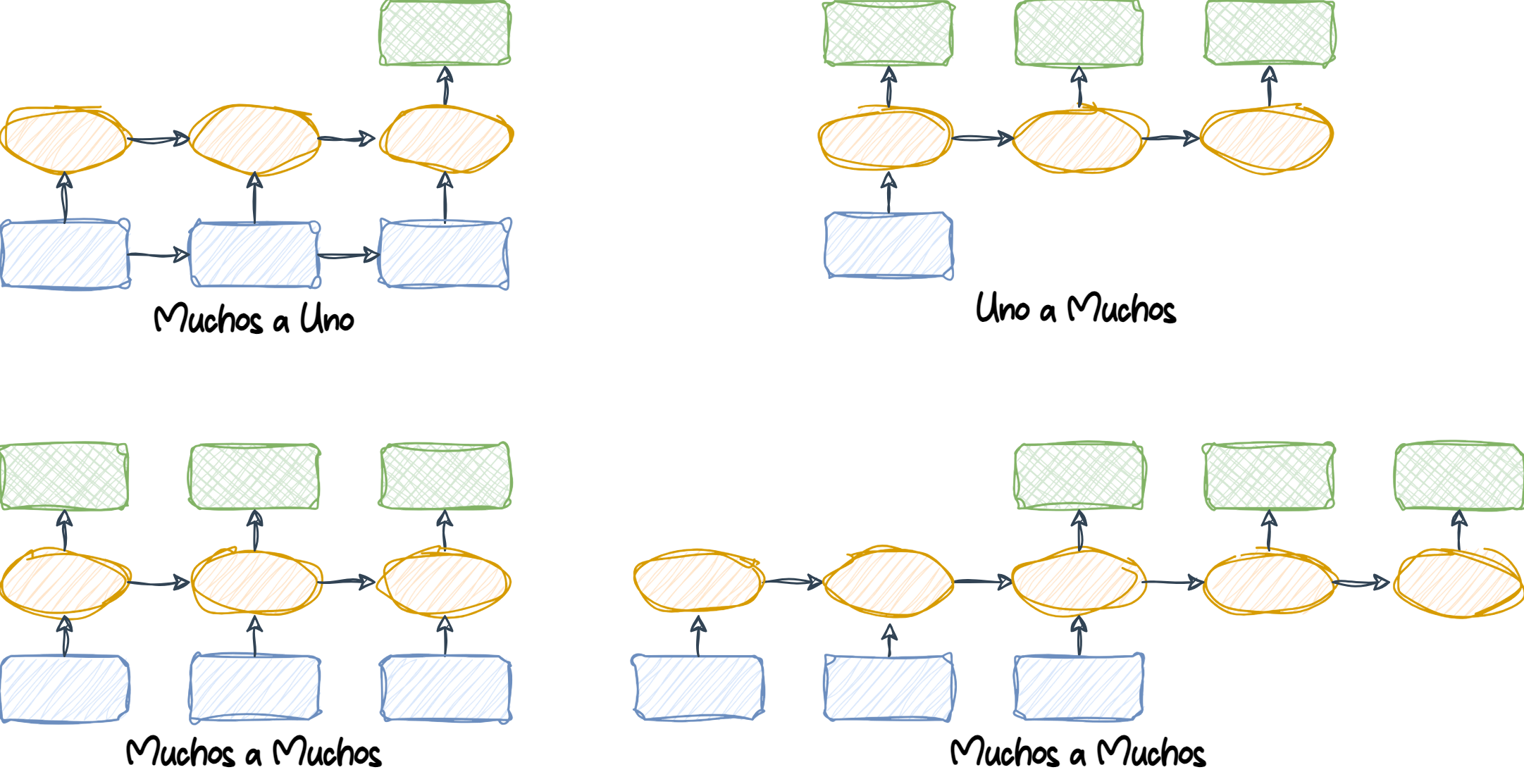
1.6.1 Muchos a uno
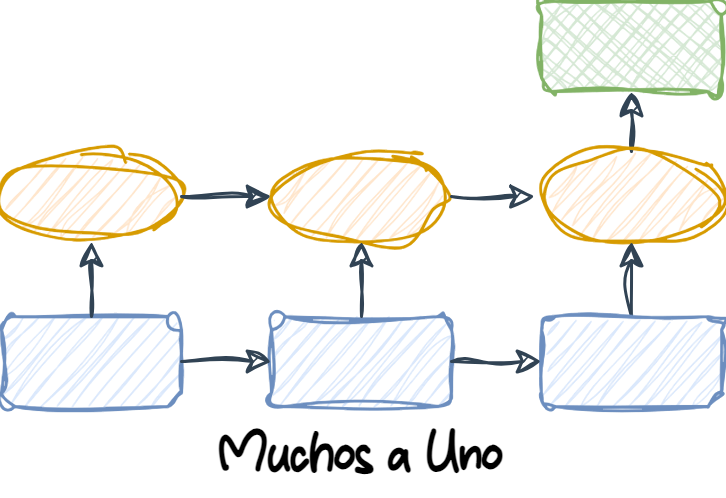
Many-to-one (Muchos a uno): Los datos de entrada son una secuencia, pero la salida es un vector o escalar de tamaño fijo, no una secuencia. Por ejemplo, en el análisis de sentimiento, la entrada es un texto (como una reseña de película) y la salida es una etiqueta de clase (por ejemplo, una etiqueta que indica si al crítico le gustó la película).
1.6.2 Uno a Muchos
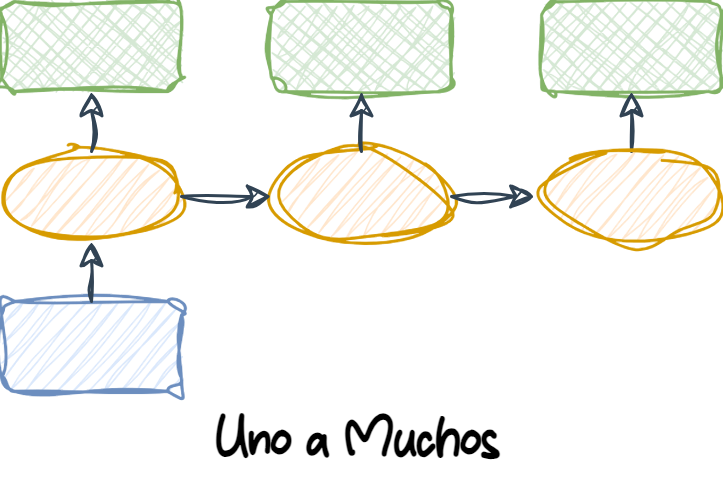
One-to-many (Uno a muchos): Los datos de entrada están en formato estándar y no son una secuencia, pero la salida es una secuencia. Un ejemplo de esta categoría es la generación de subtítulos para imágenes: la entrada es una imagen y la salida es una frase en inglés que resume el contenido de esa imagen.
1.6.3 Muchos a Muchos
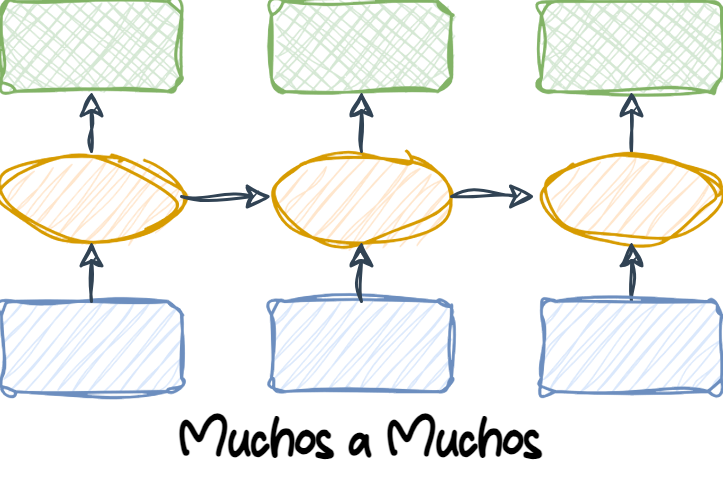
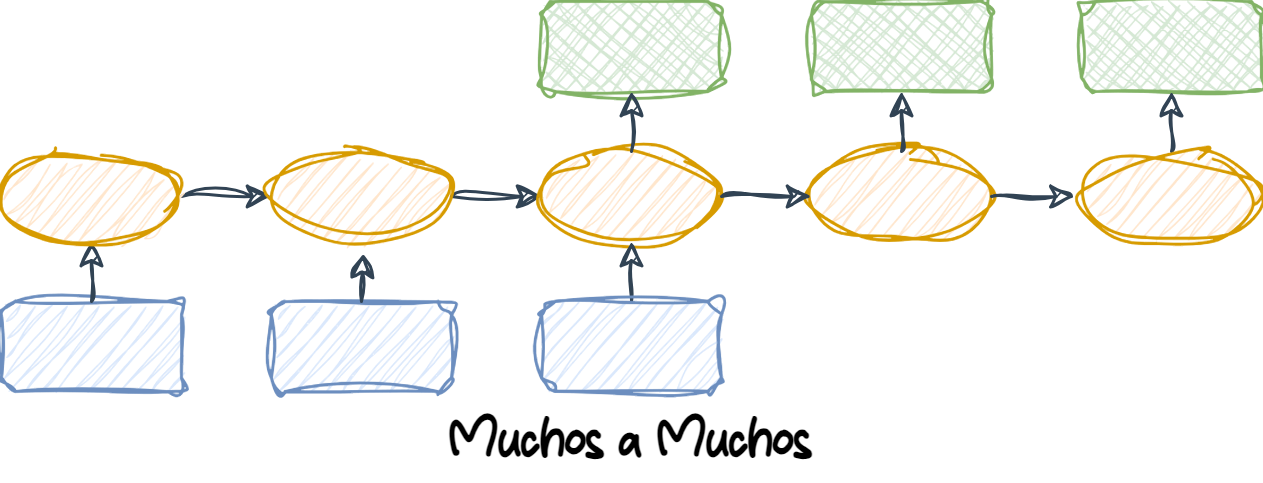
Many-to-many (Muchos a muchos): Tanto las entradas como las salidas son secuencias. Esta categoría puede dividirse aún más dependiendo de si las entradas y salidas están sincronizadas o no.
Un ejemplo de una tarea many-to-many sincronizada es la clasificación de video, donde cada cuadro en un video está etiquetado.
Un ejemplo de una tarea many-to-many con retraso sería la traducción de un idioma a otro. Por ejemplo, una frase completa en inglés debe ser procesada por una máquina antes de que se produzca su traducción al español.
2.1 Entendiendo el mecanismo cíclico de las RNNs
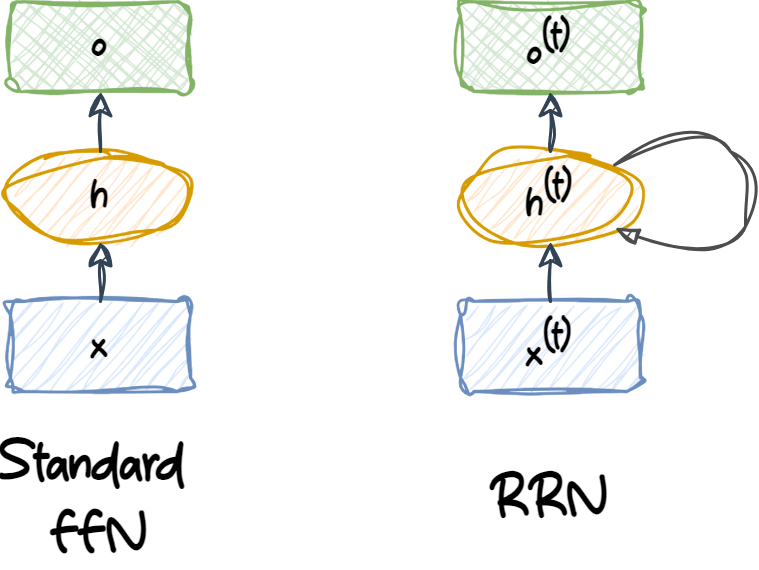
Ambas redes tienen solo una capa oculta. En esta representación, las unidades no se muestran, pero asumimos que la capa de entrada \((x)\), la capa oculta \((h)\) y la capa de salida \((o)\) son vectores que contienen muchas unidades.
Similar a los MLP, las RNN pueden consistir en múltiples capas ocultas.
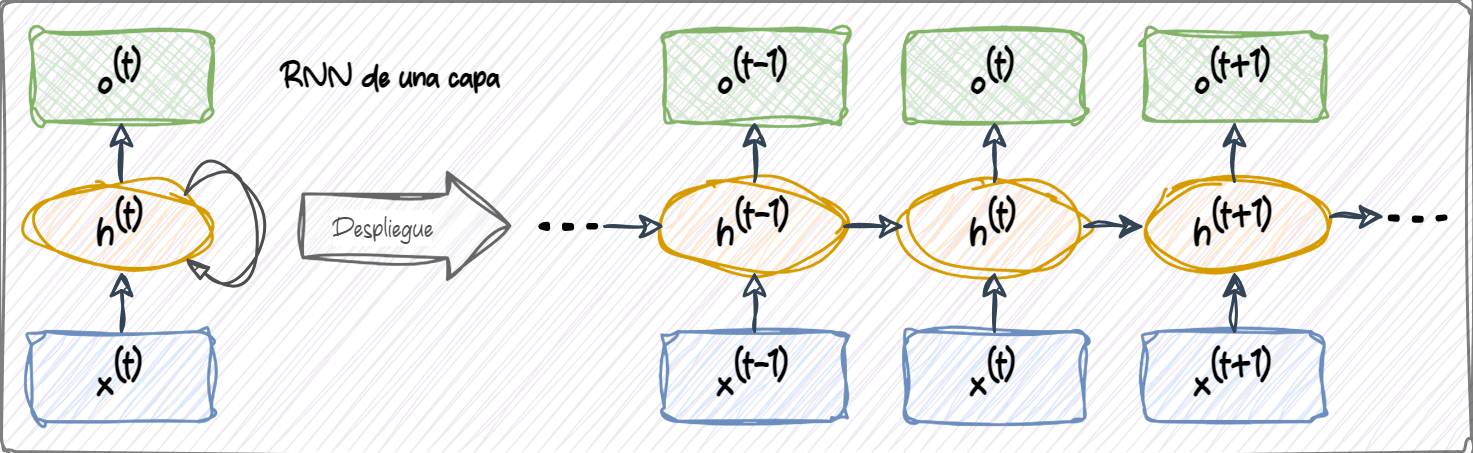
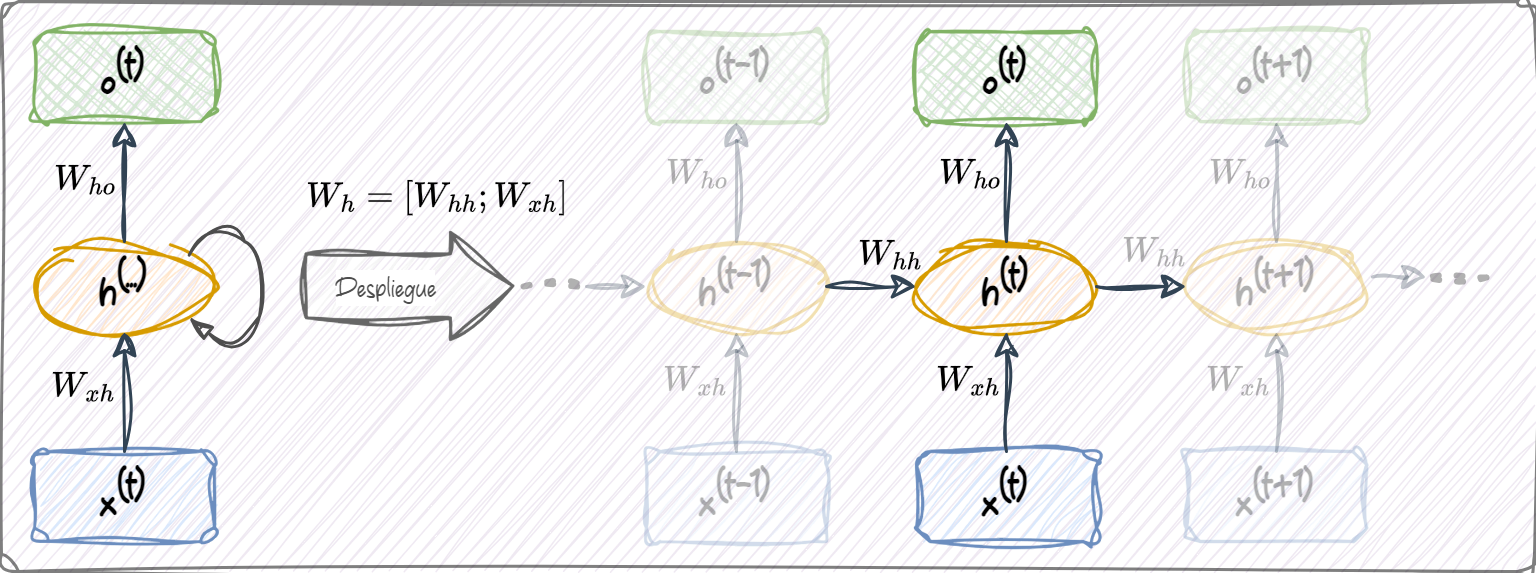
Cada unidad oculta en una red neuronal estándar (MLP) recibe sólo una entrada: la preactivación neta asociada a la capa de entrada. Sin embargo, cada unidad oculta en una RNN recibe dos conjuntos distintos de entradas: la preactivación desde la capa de entrada y la activación de la misma capa oculta desde el paso de tiempo anterior, \(t - 1\).
En el primer paso de tiempo, \(t = 0\), el estado oculto inicial usualmente se inicializa en cero o se considera un parámetro aprendible. Luego, en un paso de tiempo donde \(t > 0\), las unidades ocultas reciben su entrada desde el punto de datos en el tiempo actual, \(x^{(t)}\), y desde los valores anteriores de las unidades ocultas en \(t - 1\), indicados como \(h^{(t-1)}\).
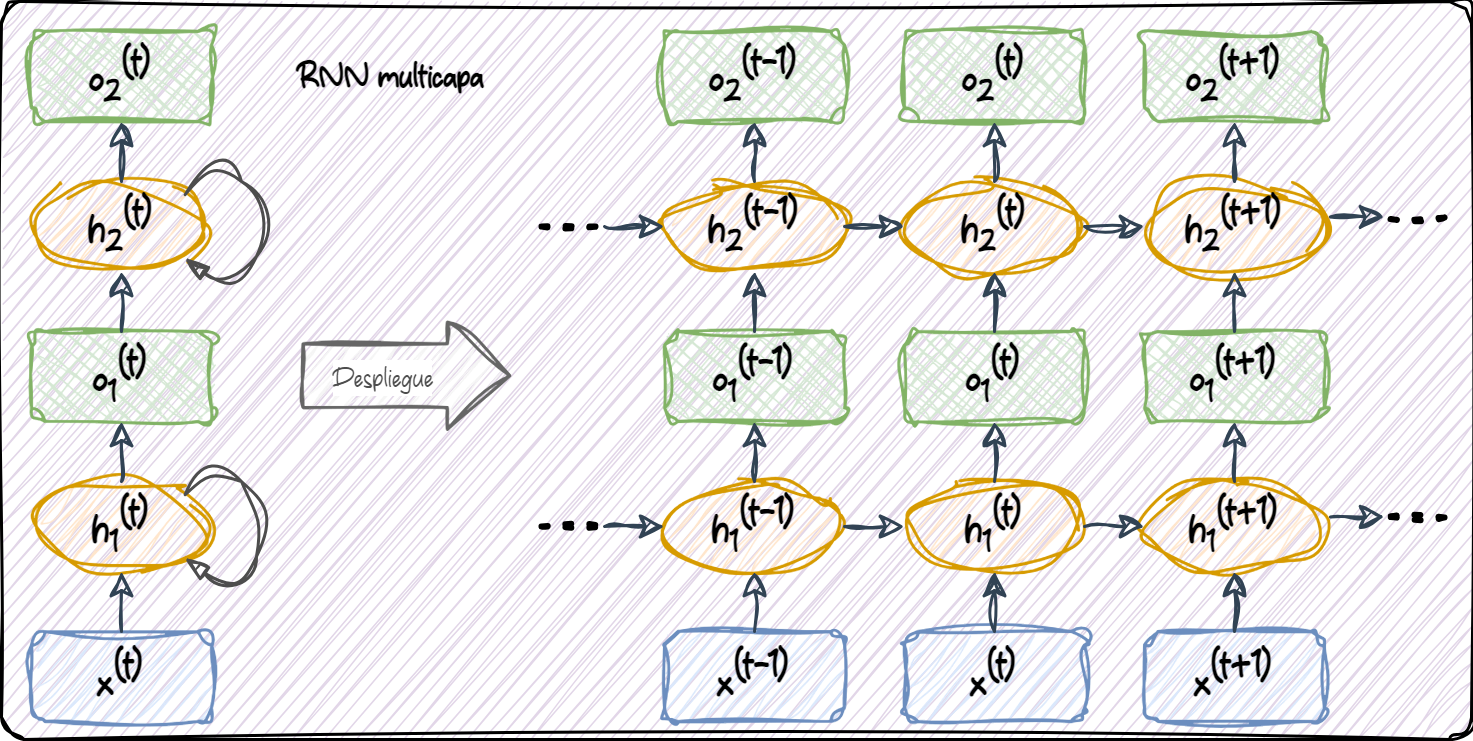
En el caso de una RNN multicapa:
capa_1: La primera capa oculta se representa como \(\mathbf{h}_1^{(t)}\) y recibe su entrada desde el punto de datos \(\mathbf{x}^{(t)}\) y desde los valores ocultos de la misma capa, pero en el paso de tiempo anterior, \(\mathbf{h}_1^{(t-1)}\).capa_2: La segunda capa oculta, \(\mathbf{h}_2^{(t)}\), recibe el estado oculto de la capa inferior en el mismo instante, \(\mathbf{h}_1^{(t)}\), junto con su propio estado oculto anterior, \(\mathbf{h}_2^{(t-1)}\).
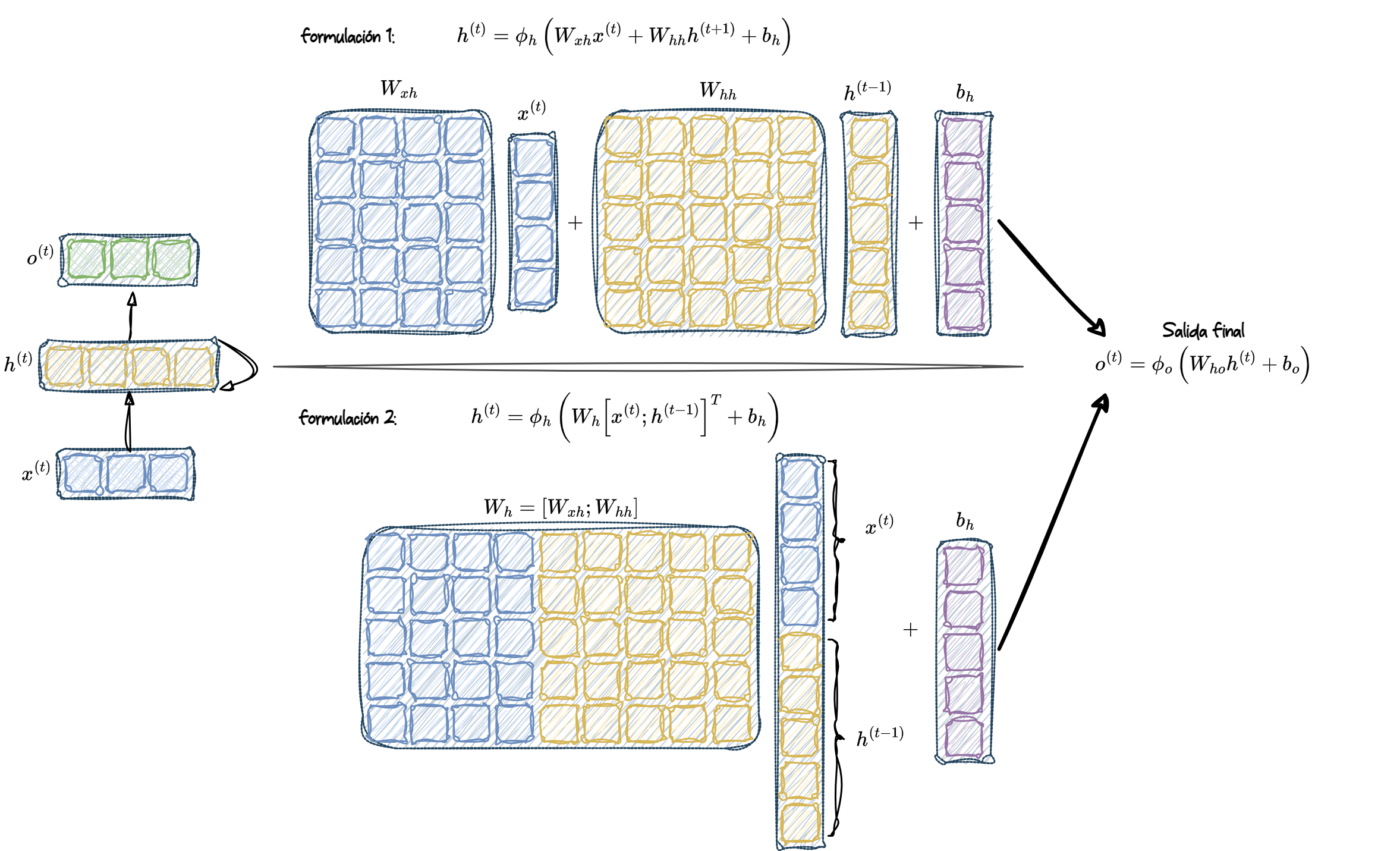
Para clarificar aún más este proceso, se muestra cómo se computan estas activaciones con ambas formulaciones.
Back propagation through time (BPTT) introduce nuevos desafíos. Debido al factor multiplicativo, \(\frac{\partial \mathbf{h}^{(t)}}{\partial \mathbf{h}^{(k)}}\), en el cálculo de los gradientes de una función de pérdida, surgen los llamados problemas de gradientes que se desvanecen (vanishing) y gradientes que explotan (exploding).
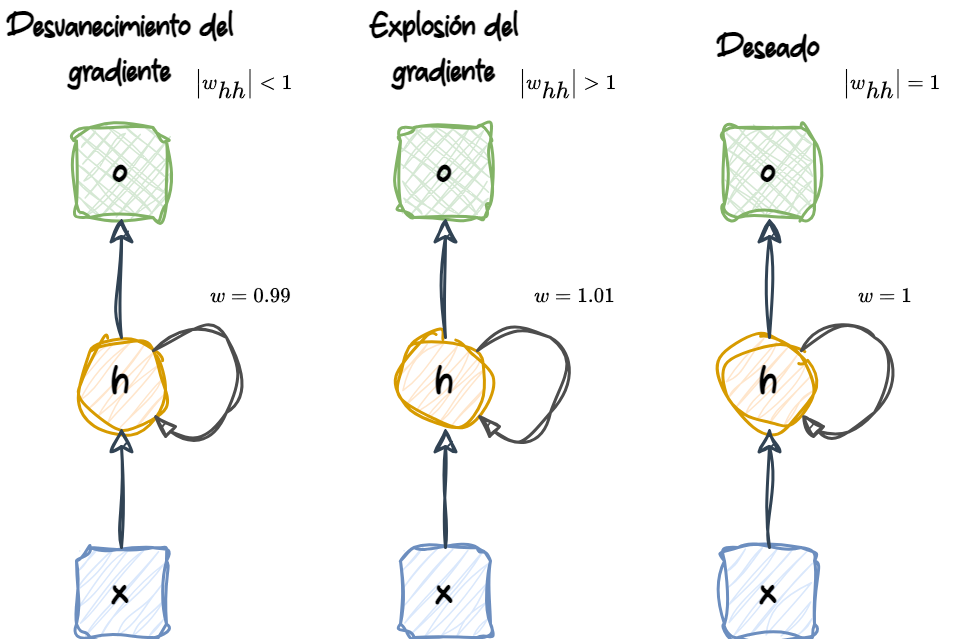

3.2.1 Un doble clic a las celdas LSTM
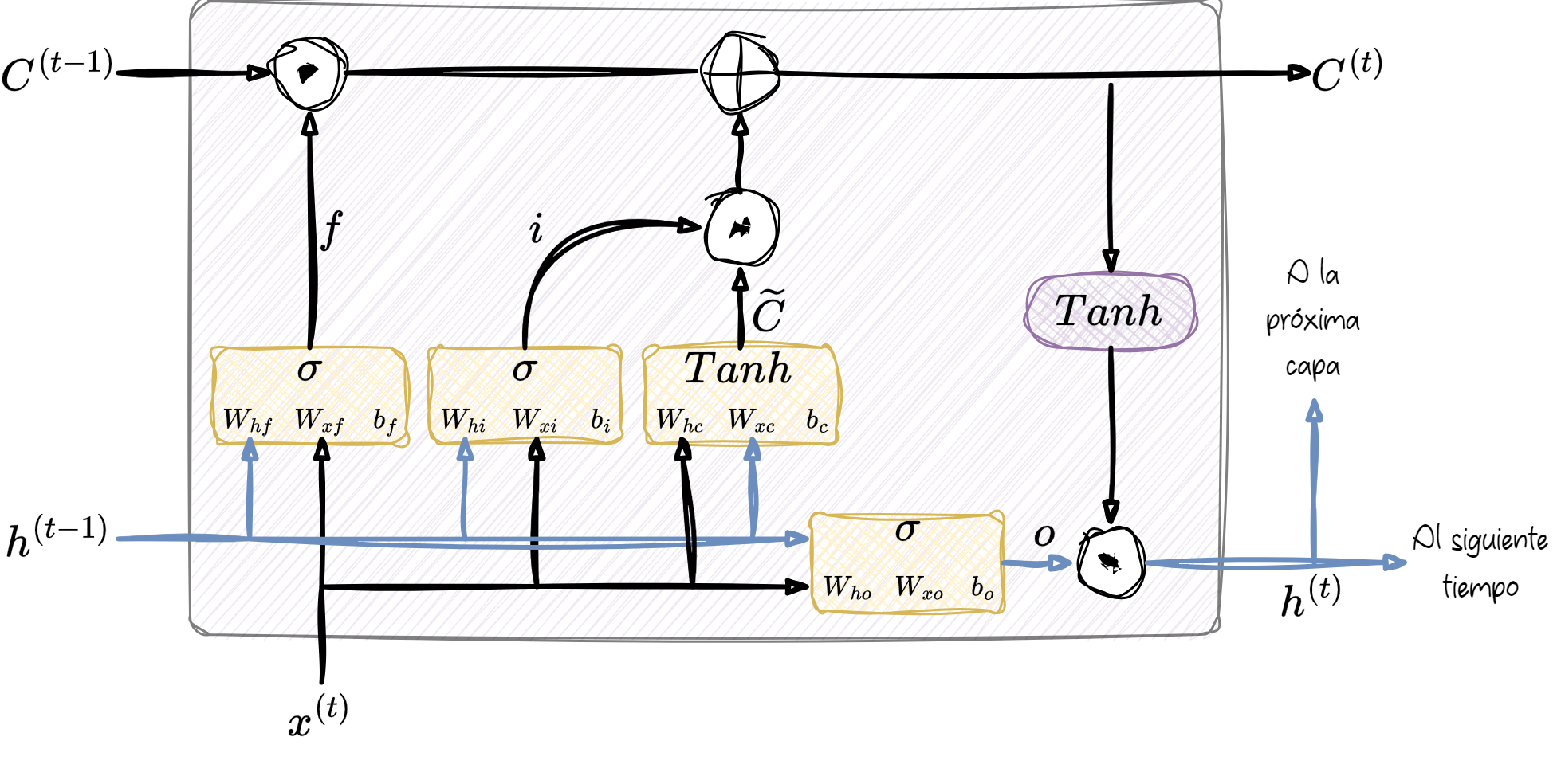
3.3 El camino del estado de la celda
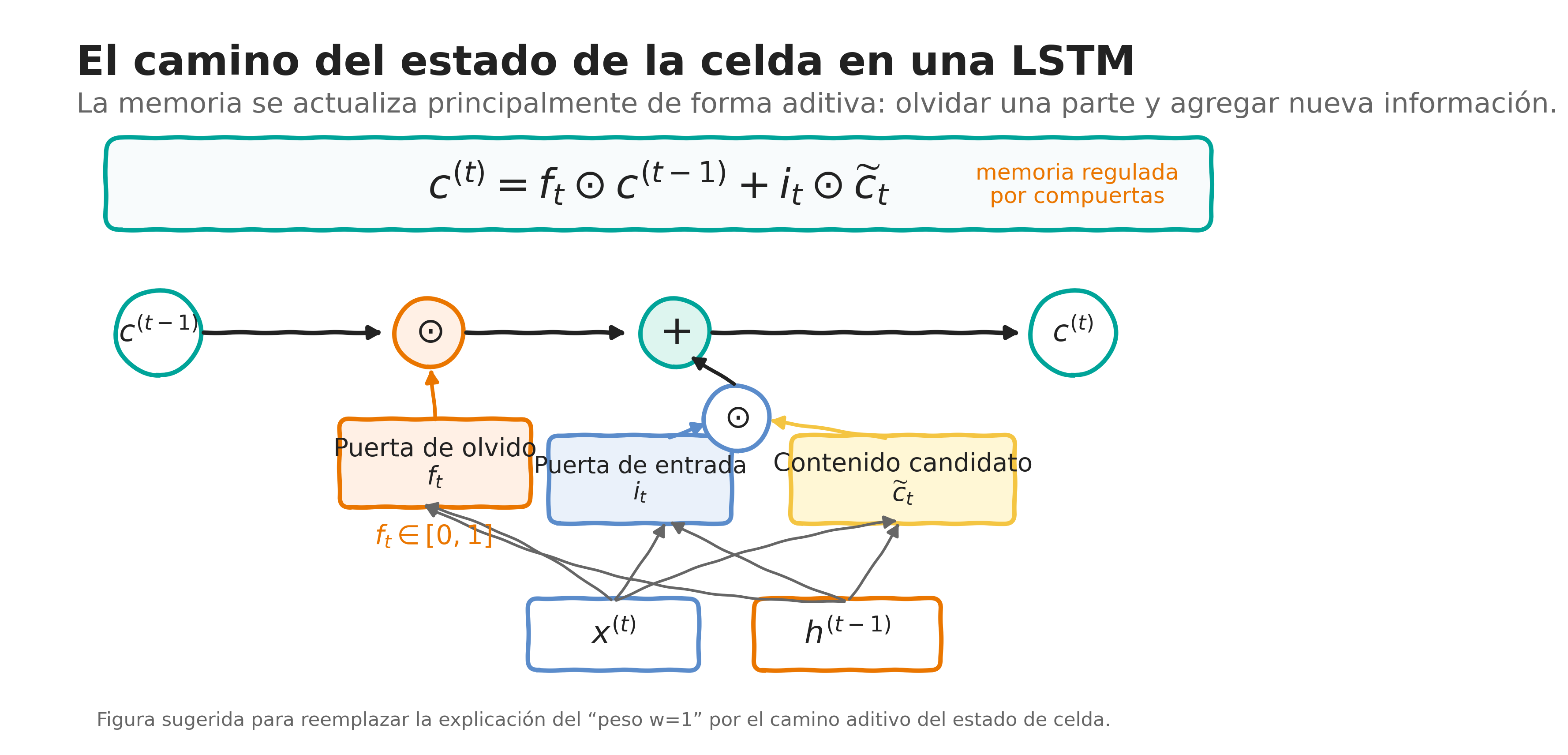
La actualización del estado de la celda tiene una estructura principalmente aditiva:
\[ \mathbf{c}^{(t)} = \mathbf{f}_t \odot \mathbf{c}^{(t-1)} + \mathbf{i}_t \odot \widetilde{\mathbf{c}}_t. \]
Esto permite que la información pueda propagarse por más pasos de tiempo cuando los valores de la puerta de olvido son cercanos a uno.
Compuertas continuas
Las compuertas no son interruptores binarios. La función sigmoide entrega valores entre 0 y 1, por lo que cada puerta regula de manera continua cuánto recordar, cuánto actualizar y cuánto exponer como salida.
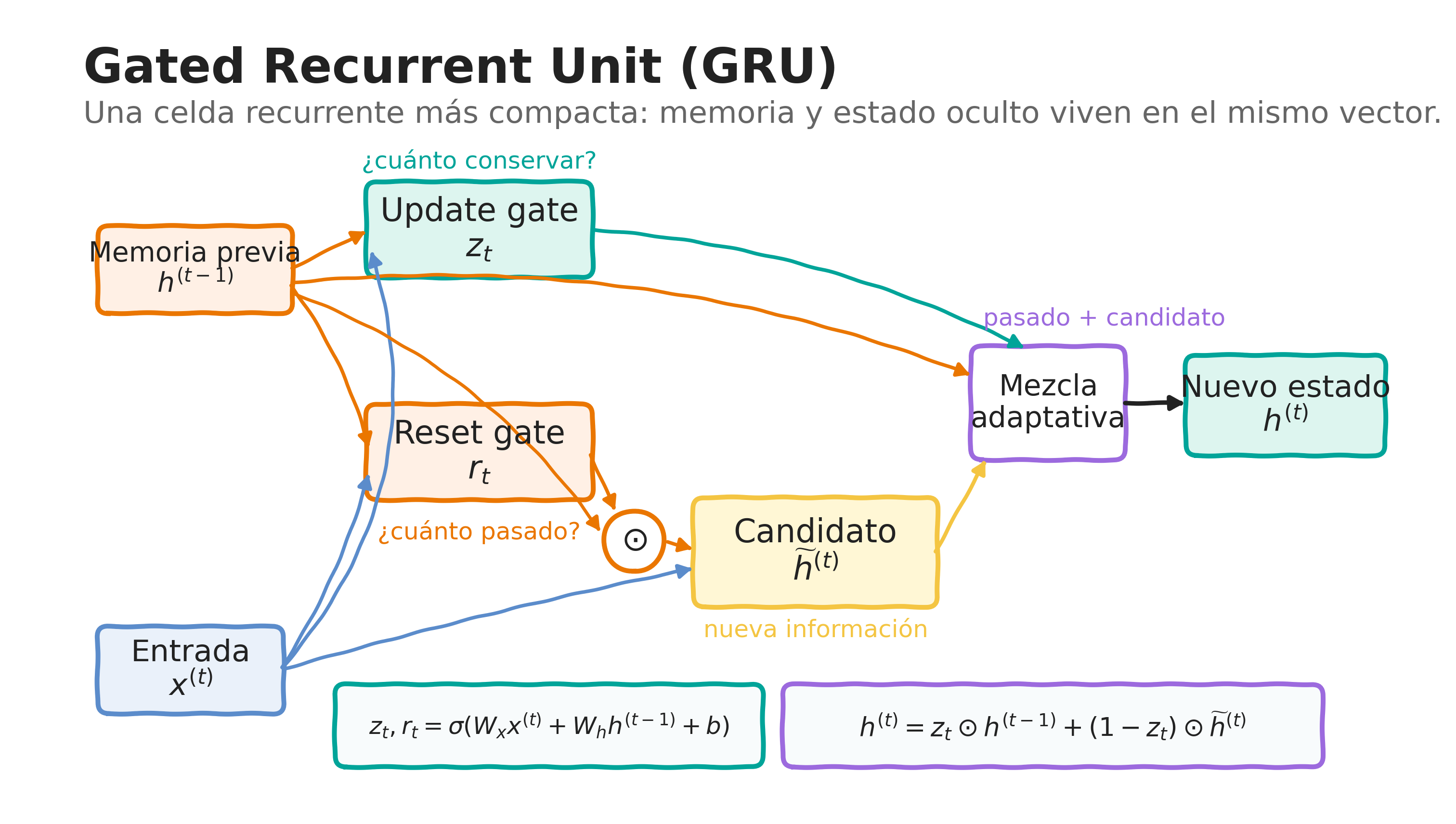
4.1 Una arquitectura recurrente más compacta
La Gated Recurrent Unit, GRU, utiliza compuertas para controlar el flujo de información, pero presenta una estructura más simple que una LSTM (Cho et al. 2014; Zhang et al. 2023).
No mantiene un estado de celda separado \(\mathbf{c}^{(t)}\).
Toda la memoria se representa mediante el estado oculto \(\mathbf{h}^{(t)}\).
Utiliza dos compuertas principales: compuerta de actualización, \(\mathbf{z}_t\), y compuerta de reinicio, \(\mathbf{r}_t\).
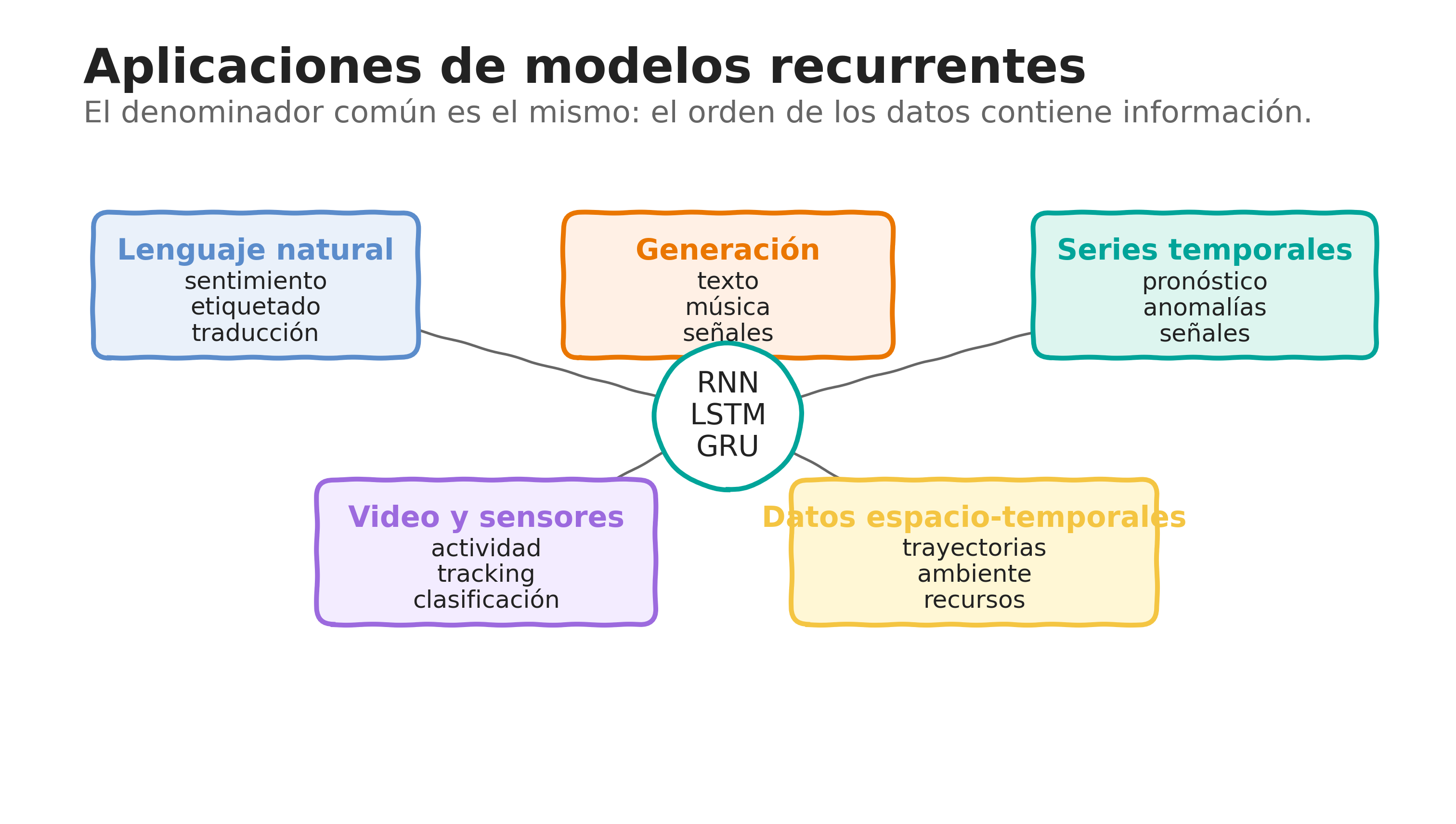
5.1 Mapa rápido de aplicaciones
5.4 Generación de texto
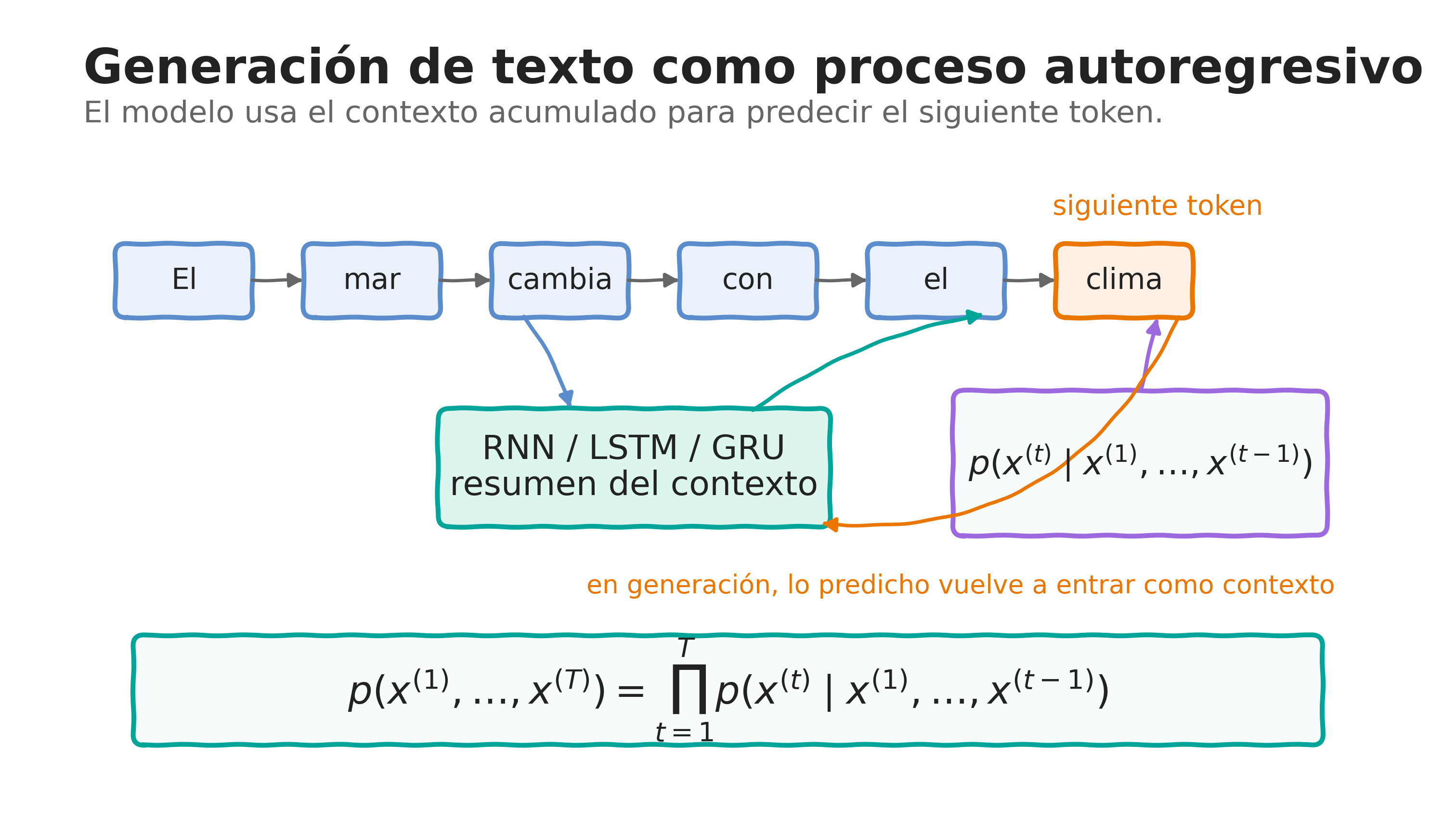
\[ p(x^{(1)},\ldots,x^{(T)}) = \prod_{t=1}^{T} p\left( x^{(t)} \mid x^{(1)},\ldots,x^{(t-1)} \right). \]
Durante entrenamiento y generación
Durante el entrenamiento puede utilizarse el elemento verdadero anterior como entrada, estrategia conocida como teacher forcing. Durante la generación, el elemento predicho se incorpora nuevamente al modelo para producir el siguiente.
5.5 RNN y LSTM para series temporales
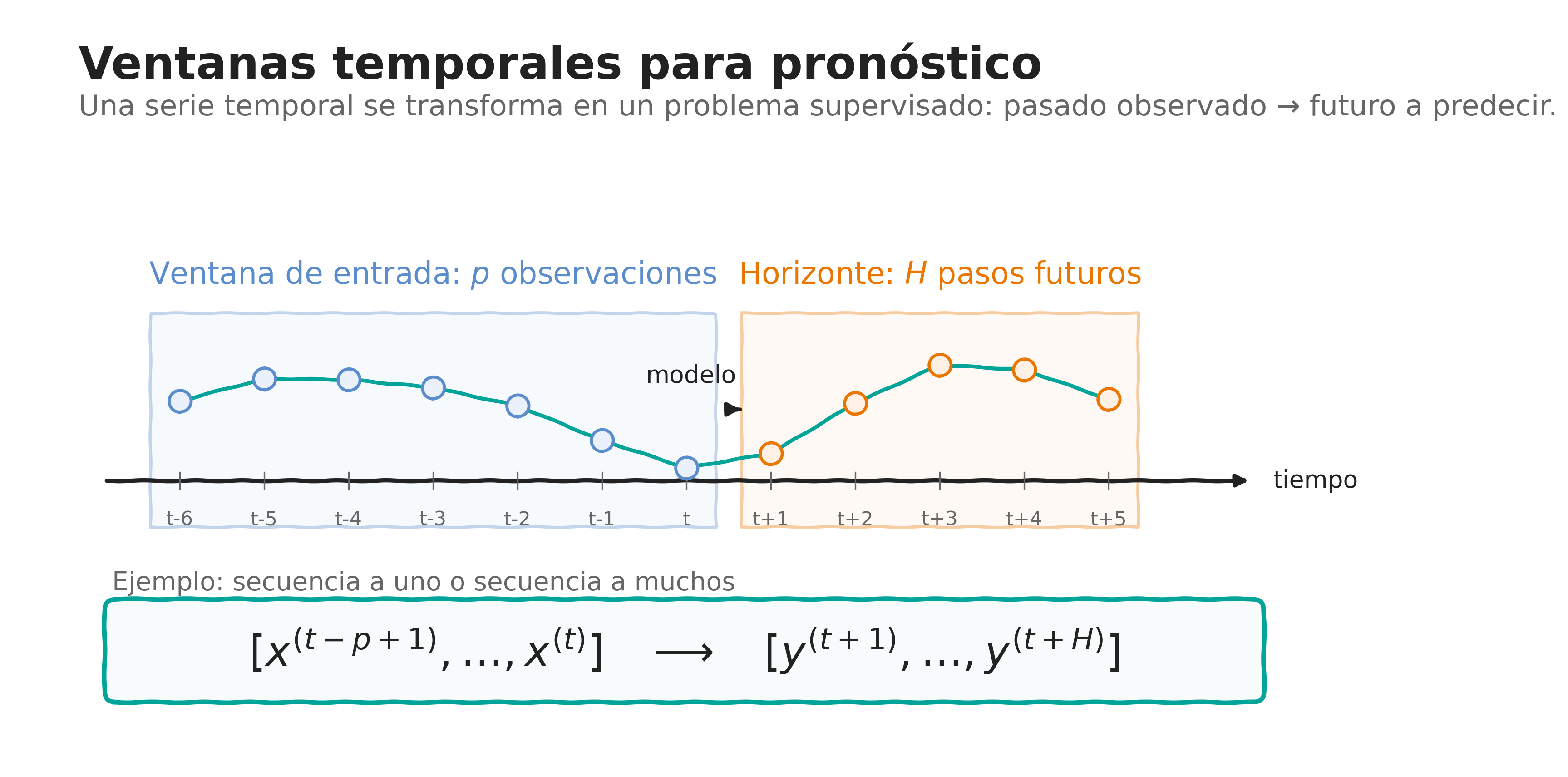
Para construir un problema supervisado, una ventana de observaciones pasadas puede utilizarse para predecir uno o varios valores futuros:
\[ \left[ \mathbf{x}^{(t-p+1)}, \ldots, \mathbf{x}^{(t)} \right] \longrightarrow \left[ y^{(t+1)}, \ldots, y^{(t+H)} \right]. \]
donde \(p\) representa la longitud de la ventana de entrada y \(H\) el horizonte de pronóstico.
